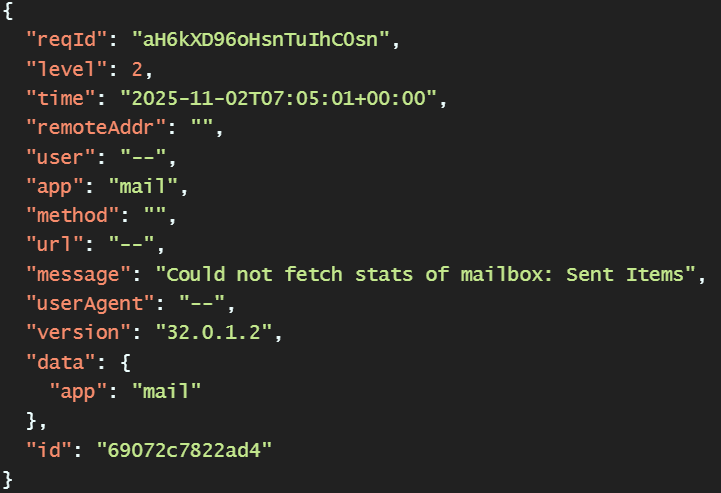
Ich habe seit kurzem* auch das Problem, dass in mein Log jede Stunde (Syncintervall) solche Warnungen geschrieben werden:
Der Log-Eintrag sieht dann so aus:
Ich habe hier mail/doc/admin.md at main · nextcloud/mail · GitHub noch einmal nachgeschaut, und habe dann folgenden Befehl ausgeführt
php -f occ mail:account:sync -vvv 1
Das Ergebnis sieht so aus:
[debug] account is up to date, skipping mailbox sync
[debug] Skipping mailbox sync for 4
[debug] Skipping mailbox sync for 5
[debug] Skipping mailbox sync for 6
[debug] Skipping mailbox sync for 1
[debug] Syncing 3
[debug] Locking mailbox 3 for new messages sync
[debug] Locking mailbox 3 for changed messages sync
[debug] Locking mailbox 3 for vanished messages sync
[debug] Running partial sync for 3
[debug] partial sync 1:Sent Items - get all known UIDs took 0s. 47/47MB memory used
[debug] partial sync 1:Sent Items - get new messages via Horde took 0s. 47/47MB memory used
[debug] partial sync 1:Sent Items - persist new messages took 0s. 47/47MB memory used
[debug] partial sync 1:Sent Items - get changed messages via Horde took 4s. 47/47MB memory used
[debug] partial sync 1:Sent Items - persist changed messages took 0s. 47/47MB memory used
[debug] partial sync 1:Sent Items - get vanished messages via Horde took 0s. 47/47MB memory used
[debug] partial sync 1:Sent Items - delete vanished messages took 0s. 47/47MB memory used
[debug] partial sync 1:Sent Items took 4s
[debug] Unlocking mailbox 3 from vanished messages sync
[debug] Unlocking mailbox 3 from changed messages sync
[debug] Unlocking mailbox 3 from new messages sync
[debug] Syncing 2
[debug] Locking mailbox 2 for new messages sync
[debug] Locking mailbox 2 for changed messages sync
[debug] Locking mailbox 2 for vanished messages sync
[debug] Running partial sync for 2
[debug] partial sync 1:INBOX - get all known UIDs took 0s. 47/47MB memory used
[debug] partial sync 1:INBOX - get new messages via Horde took 0s. 47/47MB memory used
[debug] partial sync 1:INBOX - persist new messages took 0s. 47/47MB memory used
[debug] partial sync 1:INBOX - get changed messages via Horde took 0s. 47/47MB memory used
[debug] partial sync 1:INBOX - persist changed messages took 2s. 47/47MB memory used
[debug] partial sync 1:INBOX - get vanished messages via Horde took 0s. 47/47MB memory used
[debug] partial sync 1:INBOX - delete vanished messages took 0s. 47/47MB memory used
[debug] partial sync 1:INBOX took 2s
[debug] Unlocking mailbox 2 from vanished messages sync
[debug] Unlocking mailbox 2 from changed messages sync
[debug] Unlocking mailbox 2 from new messages sync
[debug] Skipping threading as there were no significant changes
Ich sehe hier keinen Fehler und es gibt auch keinen Eintrag im Log.
Ich habe bislang keine spezielle Konfiguration für die Mail-App, sondern verwende sie ‘out-of-the-box’.
Leider habe auch ich keinen Zugriff auf die Logs des Mail-Servers (Strato)
*) Ich bin mir relativ sicher, dass ich das Verhalten seit dem Update auf NC32 beobachte.
Gibt es irgendetwas, was ich an der Konfiguration der Mail-App verändern kann?
VG SMF
System: My Cloud is at 127.0.0.1, Almalinux 9.6, Containerized mit Podman 5.4, keine AIO, Nextcloud 32, Mail 5.5.11, lokaler MTA Postfix 3.10.4, Psql 17.6, Redis 7.2.11, Nginx 1.29.3
php occ config:list | grep mail
"mail_smtpmode": "smtp",
"mail_sendmailmode": "smtp",
"mail_from_address": "***REMOVED SENSITIVE VALUE***",
"mail_domain": "***REMOVED SENSITIVE VALUE***",
"mail_smtphost": "***REMOVED SENSITIVE VALUE***",
"mail_smtpport": "25",
"emailTestSuccessful": "1",
"mail_providers_enabled": false,
"mail": {
"sharebymail": {
"mail": "5.5.11",