As I intended to shed some light on this furing my conference talk but ended up getting sick, I’ll use this opportunity instead to explain how recognize works:
How did we pull this off?
We’re not reinventing the wheel, but standing on the shoulders of giants. For most of the recognize features we’re using neural network models trained by Google. (A model in this case is a blob of math with lots of numbers, called weights. If you put in data on one end the math will calculate a result for you. That’s it.)
These are the models we’re using:
• FaceRecognizerNet by Davis King (dlib)
(99.38% Acc on Labeled Faces in the Wild dataset)
• EfficientNet v2 by Google
(83.9% top-1 accuracy on Imagenet, SOTA: 90%)
• Landmarks v1 by Google
(94,000 landmarks, accuracy varying greatly)
• MoViNet by Google
(82% top-1 accuracy on kinectics 600, SOTA: 91%)
• Custom MusiCNN
based on a paper by Jordi Pons, Xavier Serra
How do we run models in Nextcloud?
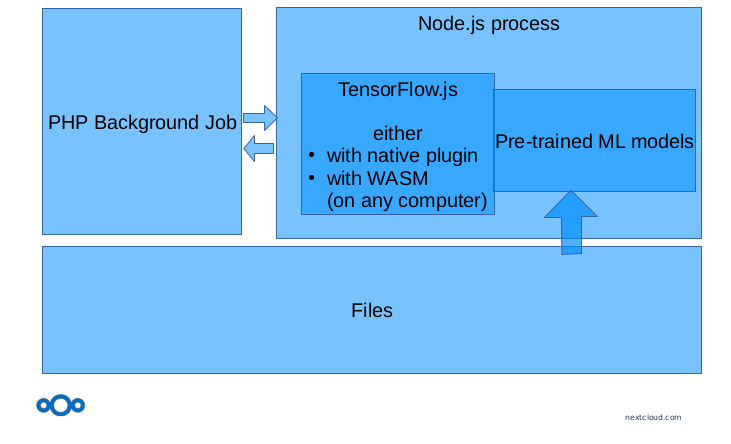
PHP does not play very nice with stuff that machine learning community comes up with, as that is mostly python code, but luckily there’s TensorFlow’s TensorFlow.js, a deep learning framework which runs in Node.js. And Node.js is a self-contained JavaScript runtime.
The recognize app comes with Node.js and executes a Node.js script from a PHP background job. That script then boots up Tensorflow with the relevant model and preprocesses the files it was passed by the PHP job and passes the result back to it. By default the model is executed in native speed using libtensorflow, but if the machine it runs on doesn’t support that we can run the model in WASM, which even works on a Raspberry Pi.
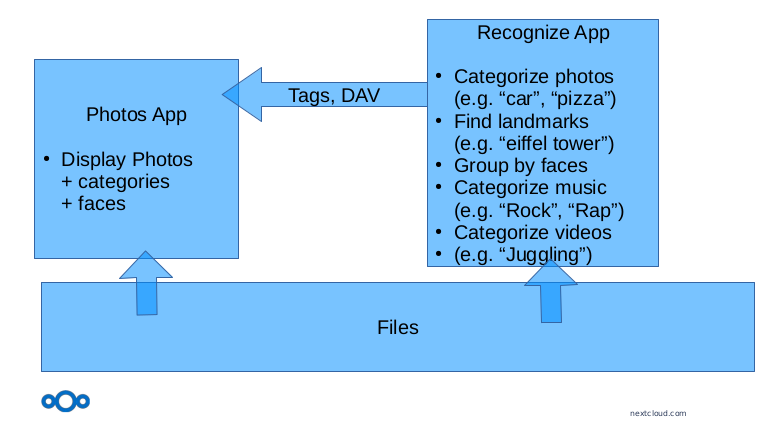
How to integrate results in Nextcloud?
How do we integrate these results in the Nextcloud UI? Most models output categories as a result, so tags lend themselves naturally as an integration point. For faces we created a webDAV endpoint that offers clusters of photos with the same face as DAV collections. This API is used by the photos app.
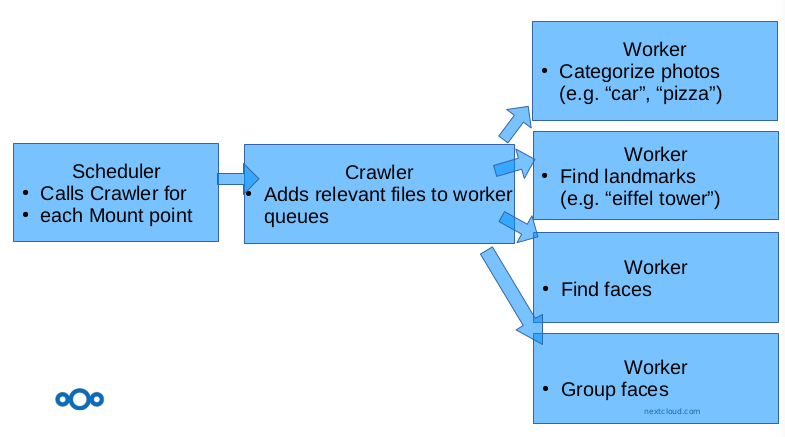
How do we make sure it scales?
And it needs to scale both up and down. For this we’ve implemented a cascade of background jobs that process both new files as well as existing files, broken up into mount points for more granular processing – the more machines you have that execute background jobs, the faster recognition will be.
Ethics
Lastly, let me say a few words about ethics. AI is hip and cool, but it is also a huge responsibility and sometimes scary. AI depends on big data collections which often infringe the privacy of service users. And AI is also often a black box: The people whose data is processes often don’t know how or why a certain outcome happens. We’re conscious of these issues and think that Nextcloud has a unique advantage for users to benefit from AI, because Open Source offers technological transparency, where users can learn how the system works and change it if they want, and Nextcloud also offers privacy, as we went out of our way to make sure your data doesn’t leave your server. Nonetheless, we’re always open for criticism, so if you have concerns, don’t hesitate to get in touch.
I hope this gives some more insight into how recognize works.
cheers!