The issue occurs when you enable OCR processing of PDF’s.
The app uses php-imagick for this process …I guess it first converts each page of PDF to an image using ImageMagick?
The problem is our accounting person uses NAPS2 to create PDFs from scanned documents. Apparently those resulting PDF files are “bad” in some way – even though they have been fine to end user forever.
When manually indexing elastic (with PDF enabled on this full text search Tesseract OCR app) … each time elastic encounters one of those otherwise-normal working PDF files from NAPS (But don’t assume NAPS is only source in world of broken PDF), the following error outputs during the indexing:
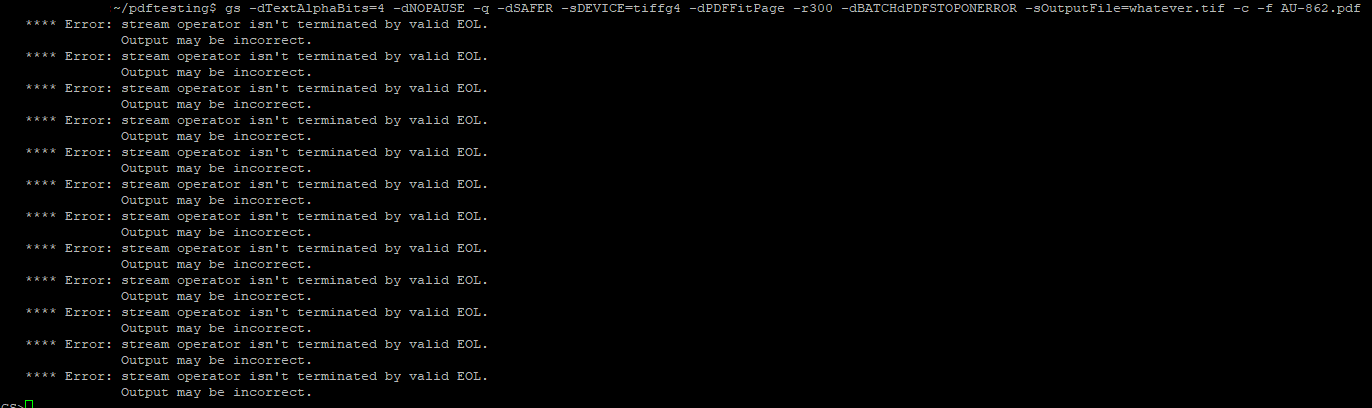
**** Error: stream operator isn’t terminated by valid EOL . Output may be incorrect.
for each “bad” PDF.
But the RESULT is, those source PDF’s were actually deleted during the process of converting them to images for processing by tesseract (!!!) Oh no.
So a better process for the Full Text Search Tesseract OCR app may be to verify the resulting OCR-enabled PDF was created before deleting the source pdf file?
Ghostscripts response is something like “well… present it with a good PDF to avoid the warning” and that seems valid. It is just a warning. However, I think it is the problem of the app in this case for assuming everything will go fine and it’s safe to delete input source files. (because it seems that this error is encountered by many people in the wild… fulltextsearch Tesseract OCR App would never know when it will be presented with one of these otherwise-good PDF files that it may ultimately delete).
Since elastic indexes the entire user file system in .data/*, having pdfs randomly be deleted like this during indexing is a nightmare scenario. Luckily we use ZFS on backend and I always take a snapshot before doing major configuration changes.
Hopefully that report and suggestions makes sense to the author.
Other than that, we had fulltextsearch working nice for a few hours today and it was amazing
I looked a little at the code for Tesseract OCR nextcloud app…
The nextcloud app uses:
To convert the pdfs to image before processing with Tesseract OCR. It is actually spatie/pdf-to-image that is using ghostscript (which is throwing the “warning”). Still, I think it would be job of the nextcloud app to determine if the pdf-to-image was successfull before destroying original pdf files.
if it helps, when I was running, I used tesseract PSM mode 12 and also had PDF limited to first 10 pages.
I will also report the issue over at github, but wanted to put warning up here since it did indeed result in unexpected removal of pdf files on our system.
Ahh @Cult… no wonder I couldn’t find your name! Ok, I’ll try to create a “bad” PDF today sometime and get you samples ASAP. Existing files have finance info so I can’t send those. I’ll probably need to set up pdf-to-image on a test server since I’ll have my head on a spike if I disappear any pdfs on the NC server again. :sigh:
@Cult have not forgot about this… my problem has been reproducing a new shareable broken or “bad” PDF that I can send you. Because it is coming from ghostscript / gs (breaking your app) I am able to easily test/repoduce the warning from command line using one of our older known “bad” pdfs…
So now you clearly see the error (at least) that causes the tesseract app to kill the files during the spatie process. Unfortunately I can not share that file, and the two I tried to create from the persons scan workstation did not produce error anymore (using both of our scanners + NAPS2). So these files that are throwing error may have been a previous employees process/apps causing the issue (I know “HP Smart Scan APP” from MS App Store was used previously here).
The problem of course is you would never know when a “old” “bad” PDF file would be indexed and deleted by your app. So now I am on a quest for a file I can share with you that generates this error so we can fix the app!
I was about to say, why would the source files be altered in any way? Deleting a source file seems an odd outcome to any scenario where something is being scanned or indexed.
We’ll see how it goes with the testing. If cult is unable to reproduce, I’ll be happy to roll a copy of my nextcloud environment (with my own combo of plugins) onto a test server and add whatever logging cult wants to include to help catch the problem.
Right now we ARE using the “Full Text search - Files - Tesseract OCR” app without PDF selected, and everything is fine.
Oh… also I thought process (in some cases, maybe not with this app?) was to embed OCR data INTO the pdf file?
I.e. NAPS2 with OCR enabled creates a PDF with embedded OCR data. I think same for Nextcloud “Optical Character recognition” app https://apps.nextcloud.com/apps/ocr ?
So in cases where you are adding OCR to a PDF, it would make sense to delete the original. However, if Cult knows this app to create a seperate FILE with OCR data, then this wouldn’t apply.
But this is a bit confusing:
read content from the pdf and generate temporary image files,
OCR those image files,
remove generated image files.
So remove the generated image files. But where does the new OCR data go?
Into a seperate file?
Into nextcloud database in a table dedicated to filename:ocr data?
Or is it to be embedded/added to the original PDF? (which would recreate the original PDF)
 Ok, I’ll try to create a “bad” PDF today sometime and get you samples ASAP. Existing files have finance info so I can’t send those. I’ll probably need to set up pdf-to-image on a test server since I’ll have my head on a spike if I disappear any pdfs on the NC server again. :sigh:
Ok, I’ll try to create a “bad” PDF today sometime and get you samples ASAP. Existing files have finance info so I can’t send those. I’ll probably need to set up pdf-to-image on a test server since I’ll have my head on a spike if I disappear any pdfs on the NC server again. :sigh: