I’ve installed NC on the SDC of my Raspberry Pi 3+. It works. Now I have attached an external 1 TB USB HDD formatted in EXT4. This drive is available in NC as an external storage.
I would like to use this external drive not as a “directory” within the NC “file system”. I want my NC to use the space on this external drive for its default structure.
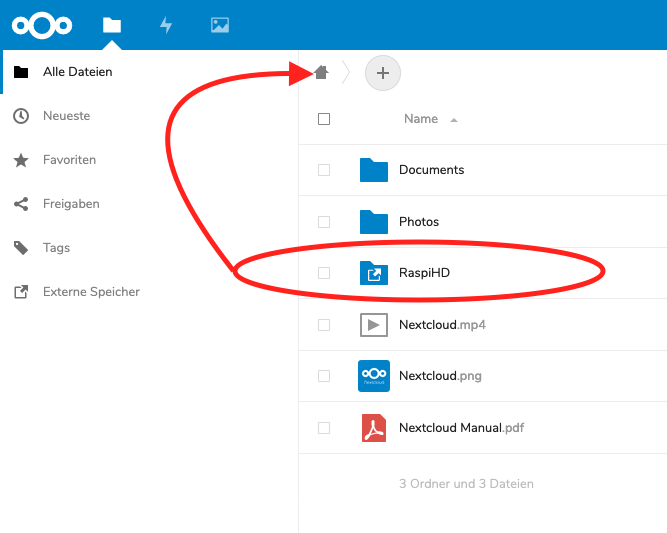
Probably I have been unable to express clearly what I mean. I’ll try it again. My USB HDD is properly mounted in /home/pi/usbdrive and is in NC available as a directory RaspiHD, as you can see here:
Oh really?
Change a line in a php file can make a web application (here is NC) access some disk space which is not defined in the web server!
What kind of expert you are? BS?
No need to rude! No disk space needs to be defined anywhere in the web server to allow web application access. Only for direct access by a web client (browser) the disk space needs to be defined as or inside web/document root in the web server. But this only includes the Nextcloud install dir itself, not the data dir, since the data dir is anyway blocked for direct access. Local PHP accesses the data dir instead and serves through web server.
The only thing you need to do is grant the webserver user (respectively PHP user) access permission and tell Nextcloud about the new data dir, which is exactly what Sonook advised correctly!
But yeah to transfer existing data and in case update the database accordingly, follow the linked HowTo.
I have never dissected operation of a web server & browser this way. Knowing the rationale behind help me to understand that it is viable and more secure than I previously thought. But still, by nature, it introduces more vector for attacker. And it is NC to bear the responsbility on this part.
NC is under very rapid and heavy development. Personally, I prefer not shifting security burden to it whenever possible.
NC is under very rapid and heavy development. Since the first day I come here, I find people asking for a wiki. Obviously, it is still not an option for NC’s operation. Users can only get bit and piece of information here and there. I follow vatolin’s link on the thread to one of your preious post, then to an even earlier post (JasonBayton, last edit 2017) where it stated something like …not officially support… Is it still valid?
It does not, it is a security enhancement since it breaks direct data access for web clients, forcing strict authentication instead.
That theoretically with faulty code attackers gain access to everything where the unix user has access to, is a nature of UNIX derivatives on the other hand. But hardening the code to prevent any such leaks is one of the main aims of Nextcloud development from the beginning.
Heavy development is done to REDUCE security burden that is present by nature on any non-fully isolated LAMP (or similar) server. Note sure which development speed you are expecting or experience elsewhere, but note that for everything related to internet protocols, a slow development is usually the security risk (IMO). New PHP versions, libraries and standards close security wholes, old encryption standards are breached by times etc. Not keeping up with all of this and your software gets as full of holes as a Swiss cheese .
This is also mentioned in the HowTo, still valid. It is also the reason you will not find it in the official documentation. The solution with the symlink (2) is not ideal since it requires to allow the webserver following symlinks to then theoretically anywhere on the system. Although on very most webservers this is allowed by default . The first solution (2) is cleaner, but it requires manual database adjustment. Since any accident with the database can break Nextcloud completely, this is as well not officially mentioned. But both methods are proven to work, just keep a backup before doing the switch, just in case.
When talk theoretically, it never ends. Too much two sides of a coin.
Regarding the How-to-FAQs, what I see is lot of effort to organize information into FAQ and presented in a forum. Personally I have used mediawiki to build a private wiki to save/retrieve/update/organize my notes. How information is organize affects a lot how people use it, especially when there is a well delivered and recognized “wiki” way. To certain extreme, in the sea of information, “everything is there” could practically equals to “nothing is there”.
Regarding the last paragraph, I understand those technical points, but don’t understand the reason why it sounds that they should not be on the official documentation.
If you are interested in the background, at least as far as I understand the behaviour (leaning by doing and reading what is relevant for my home server) and to explain why I say “theoretically”:
The webserver itself is what listens to the configured ports, usually 80 and 443 in case of HTTPS, if you forward them from router to your server, or, when being attached to the web directly, allow them to be passed through the firewall.
The webserver itself cannot do more than serving files, located in it’s configure web/document root/document directly to the clients that send requests via these ports. It is then up to the web clients (browsers) to translate the content, e.g. show HTML pages graphically, expand/show included links to local or remote pictures/sites etc., but everything still limited to what you can define via HTML and resources within the webroot.
Via modules it can control access, e.g. limit/block access to certain content, request authentication, forward requests from one resource to another etc.
But to enable access to resources outside of the webroot, or dynamic content, it needs access to separate servers and modules to connect to them correctly. Best known example, relevant for Nextcloud, is PHP. When nothing is configured and clients access a PHP file, they will simply see the raw PHP code in text format and can’t do anything with it. A PHP server needs to be installed and a related module for the webserver. Then, when a client accesses a PHP file, the webserver forwards the request/PHP pages to the PHP server. The PHP server then executes/translates the contained code/scripts etc and creates a HTML page based on the results. The webserver then sends this HTML page to the requesting client. You can verify this behaviour by using the “show source” feature of your browser when you are on your Nextcloud page. You will see HTML code that was dynamically produced by your PHP server.
The PHP server itself can access everything on your system where its UNIX user has permissions to. Furthermore it can, again via modules, access database servers (MySQL, SQLite, PostgreSQL, …) and others. What and how it accesses those, is based on the PHP code. So yeah it is then up to developers (Nextcloud) to provide code that only resolves access to the resources that are really required and translate them in a way that is most safe for client and server. This is what, IMO, requires constant and active development. Complex systems can always contain unexpected leaks or attack vectors, that is by nature. But the goal, that Nextcloud aims especially, is to detect and fix such as an ongoing process. There are/were even programs to pay out people that try to hack Nextcloud scripts and find security vulnerabilities that way. This is when the code, based on the clients requests (arguments), does things or accesses resources that are not intended.
“Theoretically” attackers can access any resource (that is available by/for PHP) by placing faulty code into your webservers webroot. But the webserver itself does not allow uploading/writing data directly when being accessed by web clients. For that local handlers like PHP and others are required, or of course FTP server and such that act totally independent of the webserver but have write access to it’s webroot as well. So this is nothing where Nextcloud can do something about. Limiting external access and local web applications to only the required ones and keeping the up-to-date with latest security patches, is responsibility of the admin of course.
Yeah I have a simple text file here where list/update all the install/config steps that I do to my server + some maintenance/debug steps. Perhaps a wiki would be more elegant/sorted but for my little home project it is sufficient and it forces me to keep it simply/tidied to not loose overview . Simple == safe/failsafe IMO.
But did you have a look into the official admin documentation? It is basically a wiki from the structure and it is fed/updated by HowTos and found/useful information by times as well via related GitHub repository. But yeah regarding to your last paragraph it is the aim to only add information that is bullet prove, does not add additional security concerns or imply the chance that you do serious damage to your system/data. This applies to the methods of transferring the data directory AFTER the install has been done.
I think It is also to reduce/limit support requests (especially in case of paid plans), so when customers do things that are not officially supported, they are on their own if something breaks. Of course if anything is included in the official docs and users/customers run into errors following these, they have good reason to complain or request support to fix etc. So it is important to define strict lines. And moving data post-install seems to imply too many (unexpected) risks to support that and allow official support requests it follow-up issues happen.
Yeah some parts of the official docs apply to that as well IMO. Some of the information is quite much scattered across different pages and not too well linked. It is not easy due to the vast amount of different possible setups. In cases I would like to have a cleaner red line for the install/setup process in a way “IF that is your case, THEN you go on here”, so one is well guided through the particular relevant pages of the wiki in a well defined order. But yeah that is usually a task for the community as well, based on their experience and their knowledge/background etc. The developers of course have their understanding/knowledge that might go far beyond usual user knowledge thus result in docs with less step-by-step character. Also with limited men power/financial resources it is always a question how much effort you want to put into documentation vs development. Finally we are in the Linux world where a certain base knowledge and in case reading/research is required to build up an own server anyway. And the particular needs/setups differ heavily.
In the end I rarely find any open source Linux software that is as well documented as Nextcloud if you take docs+forum together. I maintain/contribute to a lightweight Debian-based OS that offers automated installs for 3rd party software that usually requires a lot of manual install/setup steps. And the amount of totally limited and outdated docs and such that simply miss important dependencies or expect certain OS setups that are simply not present in most cases, is shocking. When adding ARM devices with their different manual kernel and bootloader builds and of course the incompatible CPU architectures, this becomes even worse.