I am trying to get Nextcloud to work with my Local AI installation.
I installed Local AI on my CPU only system with the following docker command:
docker run -p 8081:8080 --name local-ai -ti localai/localai:latest-aio-cpu
When I use the chat in the Local AI web interface the chat and everything else works well.
Then I tried to connect Local AI to my Nextcloud version 30.0. Here when I enter in the chat the same prompt as in the Local AI web interface nothing happens. Even if I wait for a long time. After some time I get this error in the nextcloud log.
{"reqId":"3GORAQ3AN1Dx6YespCbr","level":3,"time":"2024-09-18T09:10:21+00:00","remoteAddr":"","user":"--","app":"no app in context","method":"","url":"--","message":"Unknown error while processing TaskProcessing task","userAgent":"--","version":"30.0.0.14","exception":{"Exception":"RuntimeException","Message":"OpenAI/LocalAI request failed: Fehler bei der API-Anfrage:could not load model - all backends returned error: [llama-cpp]: could not load model: rpc error: code = Canceled desc = \n[llama-cpp]: could not load model: rpc error: code = Canceled desc = \n[llama-ggml]: could not load model: rpc error: code = Unknown desc = failed loading model\n[llama-cpp-fallback]: could not load model: rpc error: code = Canceled desc = \n[piper]: could not load model: rpc error: code = Unknown desc = unsupported model type /build/models/gpt-3.5-turbo (should end with .onnx)\n[rwkv]: could not load model: rpc error: code = Unavailable desc = error reading from server: EOF\n[stablediffusion]: could not load model: rpc error: code = Unknown desc = stat /build/models/gpt-3.5-turbo: no such file or directory\n[whisper]: could not load model: rpc error: code = Unknown desc = stat /build/models/gpt-3.5-turbo: no such file or directory\n[huggingface]: could not load model: rpc error: code = Unknown desc = no huggingface token provided\n[bert-embeddings]: could not load model: rpc error: code = Unknown desc = failed loading model\n[/build/backend/python/bark/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/bark/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/openvoice/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/openvoice/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/transformers/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/transformers/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/coqui/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/coqui/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/vall-e-x/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/vall-e-x/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/vllm/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/vllm/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/rerankers/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/rerankers/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/exllama2/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/exllama2/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/diffusers/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/diffusers/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/exllama/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/exllama/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/autogptq/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/autogptq/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/parler-tts/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/parler-tts/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/transformers-musicgen/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/transformers-musicgen/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/mamba/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/mamba/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/sentencetransformers/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/sentencetransformers/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS\n[/build/backend/python/sentencetransformers/run.sh]: grpc process not found: /tmp/localai/backend_data/backend-assets/grpc/build/backend/python/sentencetransformers/run.sh. some backends(stablediffusion, tts) require LocalAI compiled with GO_TAGS","Code":0,"Trace":[{"file":"/var/www/nextcloud/lib/private/TaskProcessing/Manager.php","line":810,"function":"process","class":"OCA\\OpenAi\\TaskProcessing\\TextToTextProvider","type":"->"},{"file":"/var/www/nextcloud/lib/private/TaskProcessing/SynchronousBackgroundJob.php","line":54,"function":"processTask","class":"OC\\TaskProcessing\\Manager","type":"->"},{"file":"/var/www/nextcloud/lib/public/BackgroundJob/Job.php","line":61,"function":"run","class":"OC\\TaskProcessing\\SynchronousBackgroundJob","type":"->"},{"file":"/var/www/nextcloud/lib/public/BackgroundJob/QueuedJob.php","line":43,"function":"start","class":"OCP\\BackgroundJob\\Job","type":"->"},{"file":"/var/www/nextcloud/lib/public/BackgroundJob/QueuedJob.php","line":29,"function":"start","class":"OCP\\BackgroundJob\\QueuedJob","type":"->"},{"file":"/var/www/nextcloud/cron.php","line":162,"function":"execute","class":"OCP\\BackgroundJob\\QueuedJob","type":"->"}],"File":"/var/www/nextcloud/apps/integration_openai/lib/TaskProcessing/TextToTextProvider.php","Line":142,"message":"Unknown error while processing TaskProcessing task","exception":[],"CustomMessage":"Unknown error while processing TaskProcessing task"},"id":"66ea9cf5cf092"}
Here is an overview of how I connected Local AI to Nextcloud:
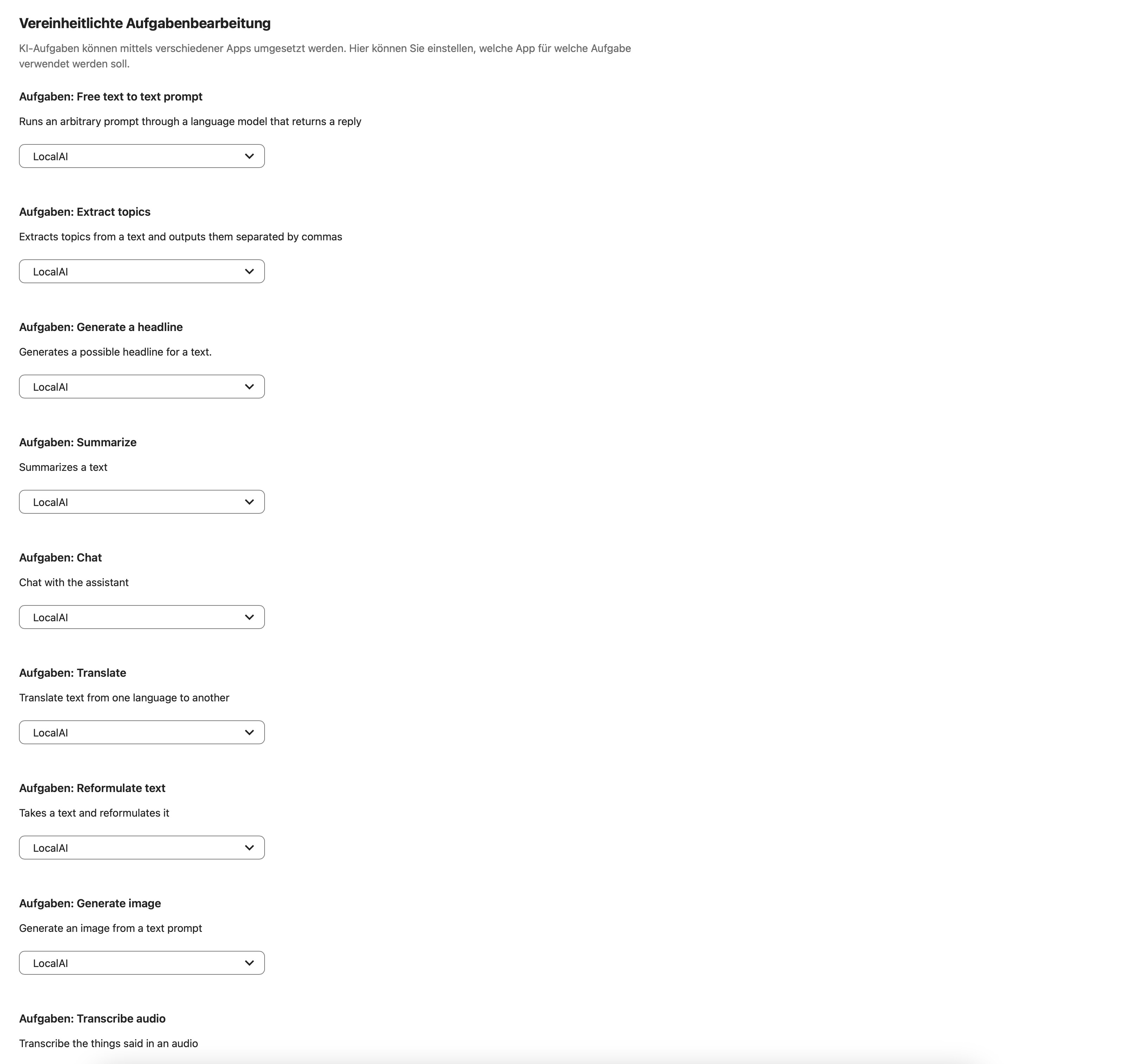
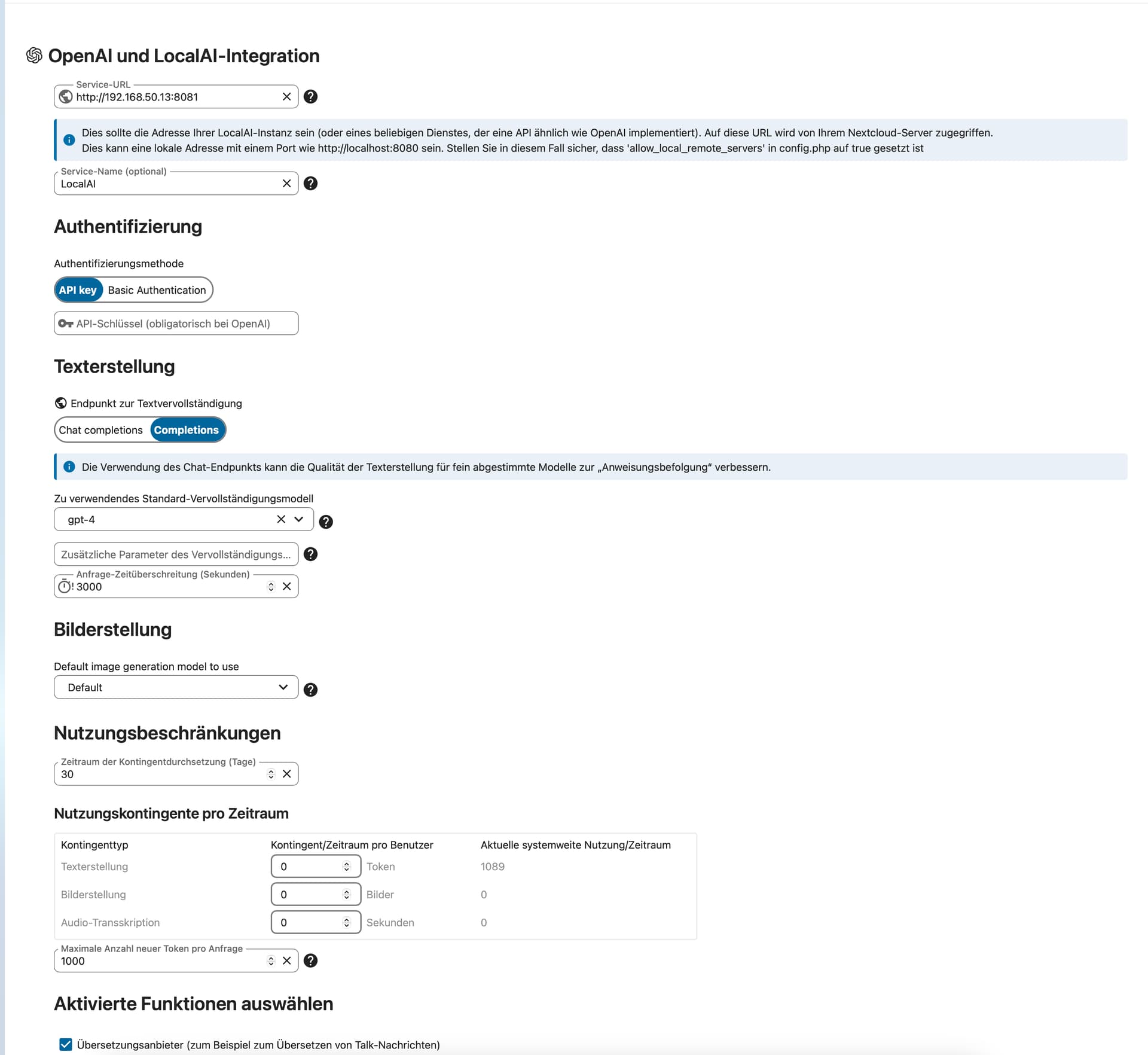
It would be great of anyone could help me getting this running ![]()