Вопрос к организации поиска в NextCloud 20
На рейде записано 700 Гб из них ~ 1 000 000 файлов. При попытке найти что-либо средствами встроенного поиска методом вставки запроса в поле, система загружает 1 поток процессора на 100%, поиск продолжается 01мин 13сек
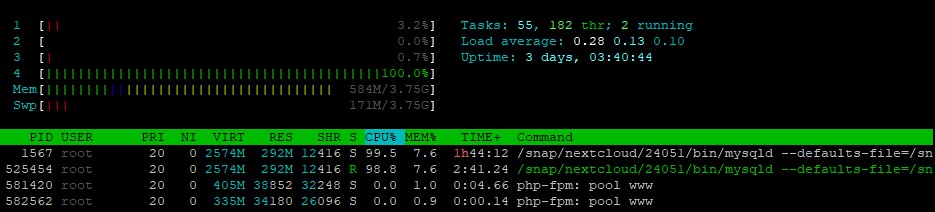
Если вводить в поле поиска название файла вручную то на поиск уйдёт уже 02 мин 13 сек при этом загружаются все 4 потока на 100% в первые полминуты, потом загрузка снижается до 50-70%.
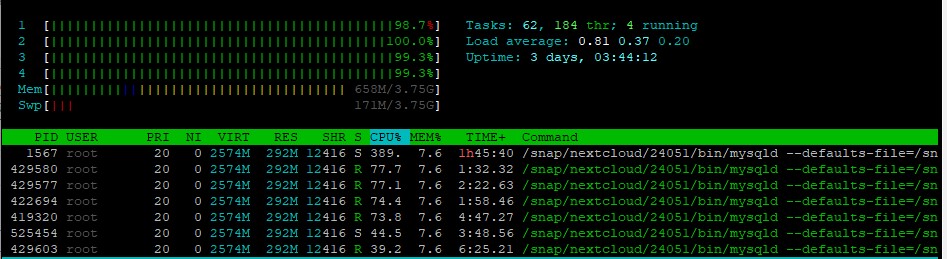
Поиск файла работает одинаково не зависимо из какой папки хранилища был запущен запрос на поиск. Допустим если я зашел в папку “\docs\photo\folder1” а в ней есть файл “img_001.jpg” и я из папки “folder1” начну искать файл “img_001.jpg”, то поиск найдет его примерно через 01мин 13сек (при условии что название файла было скопировано и вставлено в поле поиска). Если начать поиск их корня хранилища , как впрочем и из любого места то время поиска файла будет одинаково. Естественно работа поиска таким методом не позволяет комфортно им пользоваться.
А теперь вопрос, что может помочь в снижении затрачиваемого времени поиска файла?
-
Смена типа Базы данных ?
-
Смена Файловой системы? СХД
-
Установка системы на ssd рейд 0 ?
-
Поможет ли замена CPU ?
-
Существуют ли приложения/расширения для NextCloud которые ориентированы на работу с поиском информации? Искать файл рекурсивно с определенной директории, файл по дате, по размеру, по владельцу.
Тестовый стенд
i3 4160
4Gb RAM DDR3
СХД 4xHDD 500Gb RAID 10 (контроллер LSI Meda 9260) -FS EXT4
система ssd 240Gb WD-Green - FS EXT4
snap NextCloud 20
База данных mysql 5.7.32
PHP 7.4.11
UBUNTU server 20.04
Question about organizing search in NextCloud 20
The raid recorded 700 GB, of which ~ 1,000,000 files. When you try to find something using the built-in search by inserting a query into a field, the system loads 1 processor thread by 100%, the search continues for 01min 13sec
If you enter the file name manually in the search field, then the search will take 02 minutes 13 seconds, while all 4 streams are loaded by 100% in the first half a minute, then the download is reduced to 50-70%.
Searching for a file works the same regardless of which folder in the repository the search query was launched from. Suppose if I went to the folder “\ docs \ photo \ folder1” and it contains the file “img_001.jpg” and I start looking for the file “img_001.jpg” from the folder “folder1”, then the search will find it in about 01min 13sec (when provided that the file name has been copied and pasted into the search field). If you start searching for their repository root, as well as from anywhere, then the file search time will be the same. Naturally, the search work using this method does not allow it to be used comfortably.
Now the question is, what can help in reducing the time spent searching for a file?
Changing the Database Type?
File System Change? Storage
System installation on ssd raid 0?
Will replacing the CPU help?
Are there applications / extensions for NextCloud that are focused on working with information retrieval? Search for a file recursively from a specific directory, file by date, by size, by owner.
Test stand
i3 4160
4Gb RAM DDR3
Storage 4xHDD 500Gb RAID 10 (LSI Meda 9260 controller) -FS EXT4
ssd system 240Gb WD-Green - FS EXT4
snap NextCloud 20
Mysql database 5.7.32
PHP 7.4.11
UBUNTU server 20.04