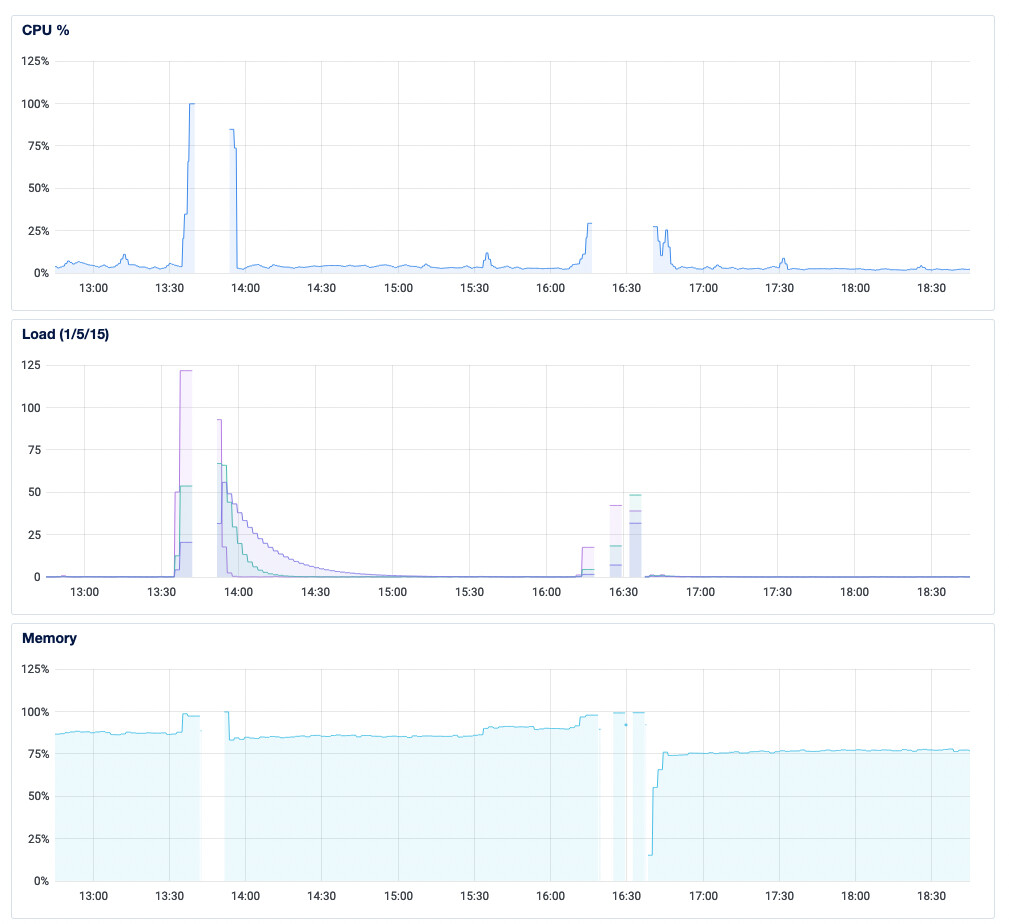
I haven’t been happy with my existing Nexcloud that I set up on an Nginx webserver that is concurrently serving several other sites, so over the weekend I set up a brand new Nextcloud All-In-One instance on its own VM. It seemed fine, but now in the last 12 hours it has totally frozen twice, making it completely unusable and unreliable. Before I lose another day or two troubleshooting, I thought I’d ask here and give my basic configuration specs to see if anyone sees any red flags.
VM:
- Digital Ocean Droplet: 2vCPUs / 2GB memory / 60GB storage
- OS: Ubuntu 22.04
- Firewall: UFW enabled with all appropriate ports opened
Nextcloud AIO:
- Channel: beta
- BorgBackup: daily backups enabled and showing no issues
- Approximate size of files: 5GB
- Extras: Collabora (Nextcloud Office) & Talk (tho not actually using Talk)
I’ve tried to share a Collabora doc with someone and CPU was above 100%, everything froze. This has happened a couple times now.
Is it worth going back to ‘latest’ channel instead of beta? Anything else that would be suspect in the setup?
Looking at the log (which I mostly don’t understand) I do see this repeatedly:
206.84 - - [27/Jun/2022:22:25:49 +0000] "GET / HTTP/1.0" 400 622 "-" "-"
:"info","ts":1656369389.5331867,"logger":"tls.on_demand","msg":"obtaining new certificate","server_name":"172.17.0.8"}
:"info","ts":1656369389.5337017,"logger":"tls.obtain","msg":"acquiring lock","identifier":"172.17.0.8"}
:"info","ts":1656369389.5382826,"logger":"tls.obtain","msg":"lock acquired","identifier":"172.17.0.8"}
:"error","ts":1656369389.5390816,"logger":"tls.obtain","msg":"will retry","error":"[172.17.0.8] Obtain: subject does not qualify for a public certificate: 172.17.0.8","attempt":1,"retrying_in":60,"elapsed":0.000758175,"max_duration":2592000}
:"error","ts":1656369449.5412323,"logger":"tls.obtain","msg":"will retry","error":"[172.17.0.8] Obtain: subject does not qualify for a public certificate: 172.17.0.8","attempt":2,"retrying_in":120,"elapsed":60.002909623,"max_duration":2592000}
:"info","ts":1656369569.53684,"logger":"tls.obtain","msg":"releasing lock","identifier":"172.17.0.8"}
Is there something with the the certificate? And if so, how to solve?
Many thanks in advance for any suggestions!