Dear All,
First of all, thank you in advance for Your time on this.
I am trying to setup PDF full image/text search (some PDFs are just images and not text) in my NextCloud 25.0.6 instance. It runs on Rokcy Linux 8 (fully updated) as a web page, served by the host’s apache server (not running as container image or virtual image).
Googling around and searching in this forum, I started by installing Tesseract and adding the English language for start.
Under Admin → Administration → Full Text Search, I could see nothing but “General Settings” with the “Search Platform” empty. Also show in the bellow screenshot.

Then again looking for information in the Wiki I concluded (maybe wrongly?) that I have to install ElasticSearch.
So I did.
At that point, the Search Platform option could be populated (Elasticsearch was an option) and only then the Tessearct OCR options became available.

All the above, as the admin user.
I do have a small doubt about the elasticsearch part specifically the url setting as the installation is using certs for authentication:

Now I login as a non-admin user and create a flow.

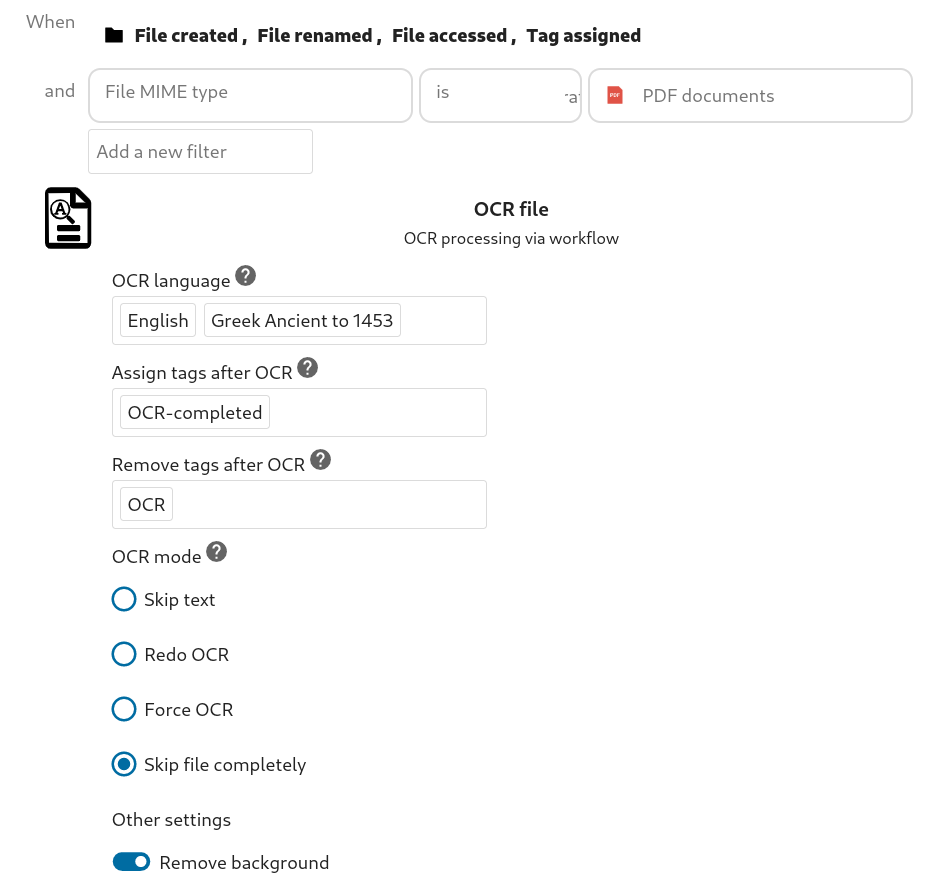
And I also add the following with crontab -u apache -e:
*/5 * * * * php -f /mnt/services//www/html/nextcloud/cron.php
At this point I expect as a non admin user:
- Adding the OCR tag to a pdf file, this to be OCRed.
- Searching words contained in the pdf (English language pdf) to return results pointing to that document
- The cron job to do something (but what???)
What I actually have is:
- Adding the OCR tag to a pdf, does not seam to OCR it.
- The disks are 100% active. Tools for tracing activity (iotop, top, ps etc) show that there
php -f /mnt/services//www/html/nextcloud/cron.phpis running all the time (doing what?) and mariadb is constantly updating tuples.
So my questions:
- Do I correctly think that Tessaract ocr will actually fully ocr any English pdf document with the OCR tag assigned to it?
- Are the above steps take correct towards that?
- Am I missing something?
- Do I have a correct test case (assign the OCR tag to a pdf & wait for it to be indexed)?
- Where does elasticsearch fit in the setup?
- Why is the system (cron.php / mysql) so busy? Doing what? How to find out?
Much appreciated.
Cheers,
Theo