ich benutze Nextcloud auf meinen Linux-Server (Debian 8). Nextcloud ist die ausschließlich gefahrene Anwendung auf dem Server. Läuft über Apache2. Der Server hat 8 GB Arbeitsspeicher.
Ich muss allerdings feststellen, dass der Arbeitsspeicher mit der Zeit immer geringer wird. Nach einem Neustart sind 668 MB genutzt, nach einigen Tagen sind bereits 2.1 GB genutzt, Tendenz weiter steigend, bis der Server letztlich nicht mehr erreichbar ist, ausser über SSH.
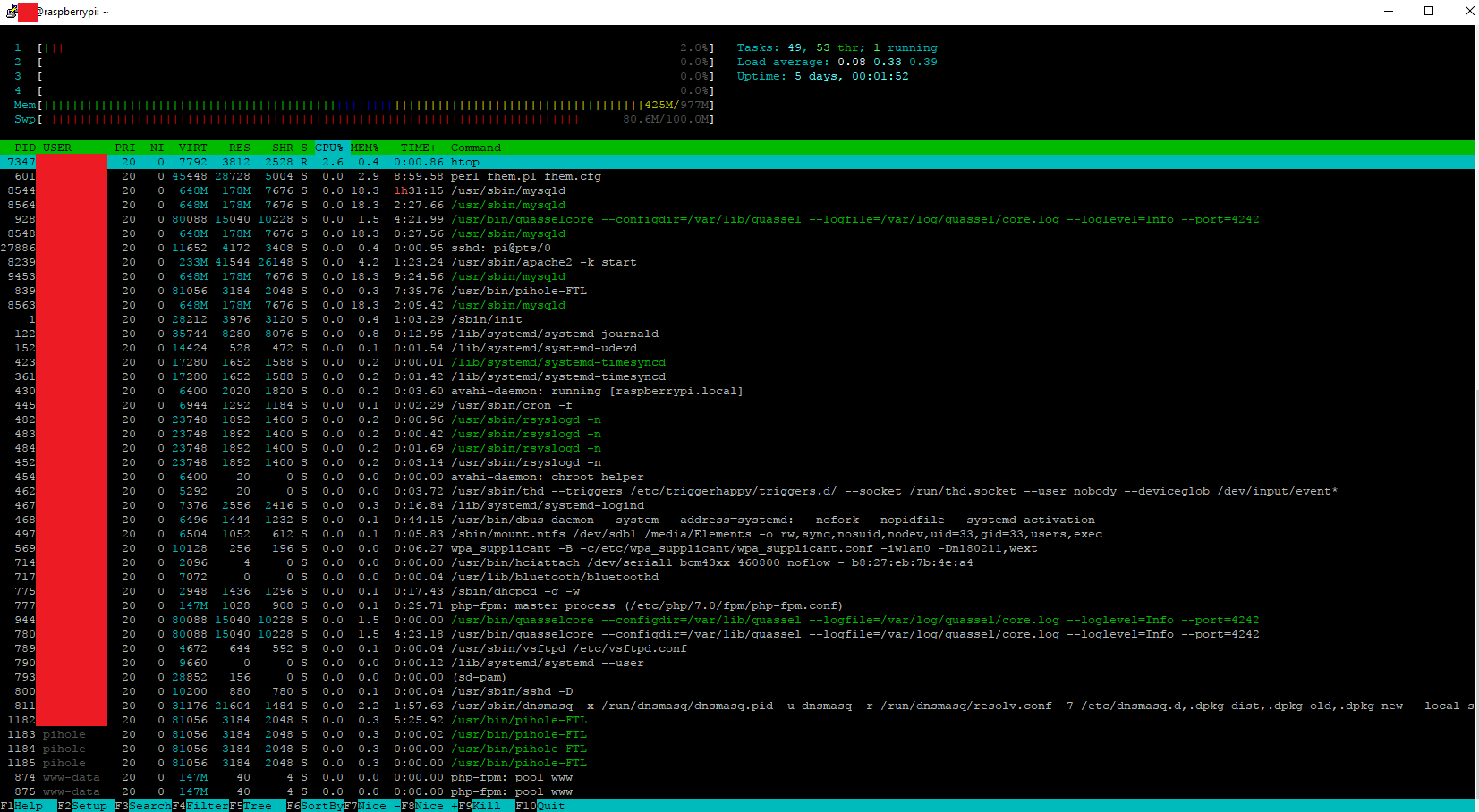
Nein, sowas bis jetzt nicht. Ich benutze ein Raspberry Pi 3 und dieser hat nur 1 Gigabyte. Dazu habe ich 100 Mb Swapspeicher. Aber selbst bei 2.1 GB sollte der Server dennoch erreibar sein. Was hast du denn noch für Applicationen am laufen?
Es läuft noch Plesk (ich bin ein wenig faul ) aber sonst laufen dort keine weiteren Applikationen. Diesen Server habe ich ausschließlich Nextcloud zur Verfügung gestellt.
Dennoch vorsichtshalber mal ein ps -e:
Unter Linux funktioniert das mit TOP. Besser und grafisch ansehnlicher finde ich noch htop. Dort sieht man direkt welcher Prozess, was “zieht”.
Bei mir siehts so aus: @raspberrypi:~ $ free -lh
total used free shared buff/cache available
Mem: 976M 387M 45M 38M 543M 491M
Low: 976M 931M 45M
High: 0B 0B 0B
Swap: 99M 78M 21M
Ich bin also relativ am Limit Jedoch muss ich noch sagen, dass ich noch pihole benutze als zusätzlichen DNS Server im Heimnetz und noch eine fhem Instanz. Das gelbe vom Ei ist es natürlich nicht und die Webseiten sind natürlich auch nicht das schnellste, aber das wesentliche, die Synchronisation über Webdav funktioniert bei mir sehr flott .
Ich glaube es liegt dabei echt an Plesk, weil Plesk die ganzen Systeme, soweit ich weiß, auch noch überwacht und dabei mitloggt.
Was ich mir noch vorstellen kann, ist ein fehlendes Logrotate
Ich sollte aber in Fhem auch die Logs nach MySQL umziehen würd meinen Pi auch um einiges Performanter machen. Habe den eh letzten Monat neu aufgesetzt, und ich kam auch noch nicht dazu einen Cache zu installieren. Sprich APCu und Redis
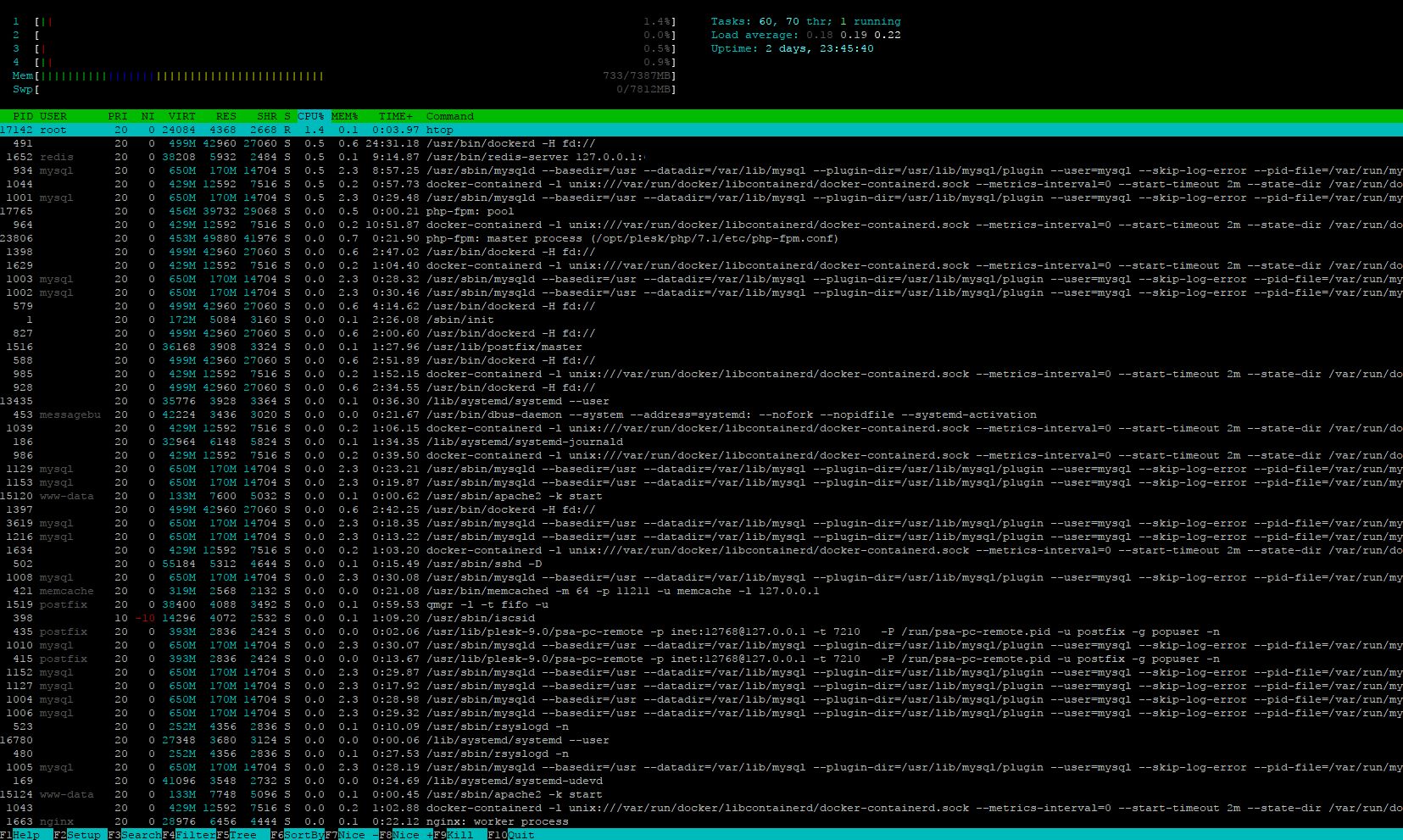
@My1 MySQL hat ein anderes thread-Modell als Apache.
Hier ist die Anzahl nicht wirklich zu regulieren.
Quelle Google
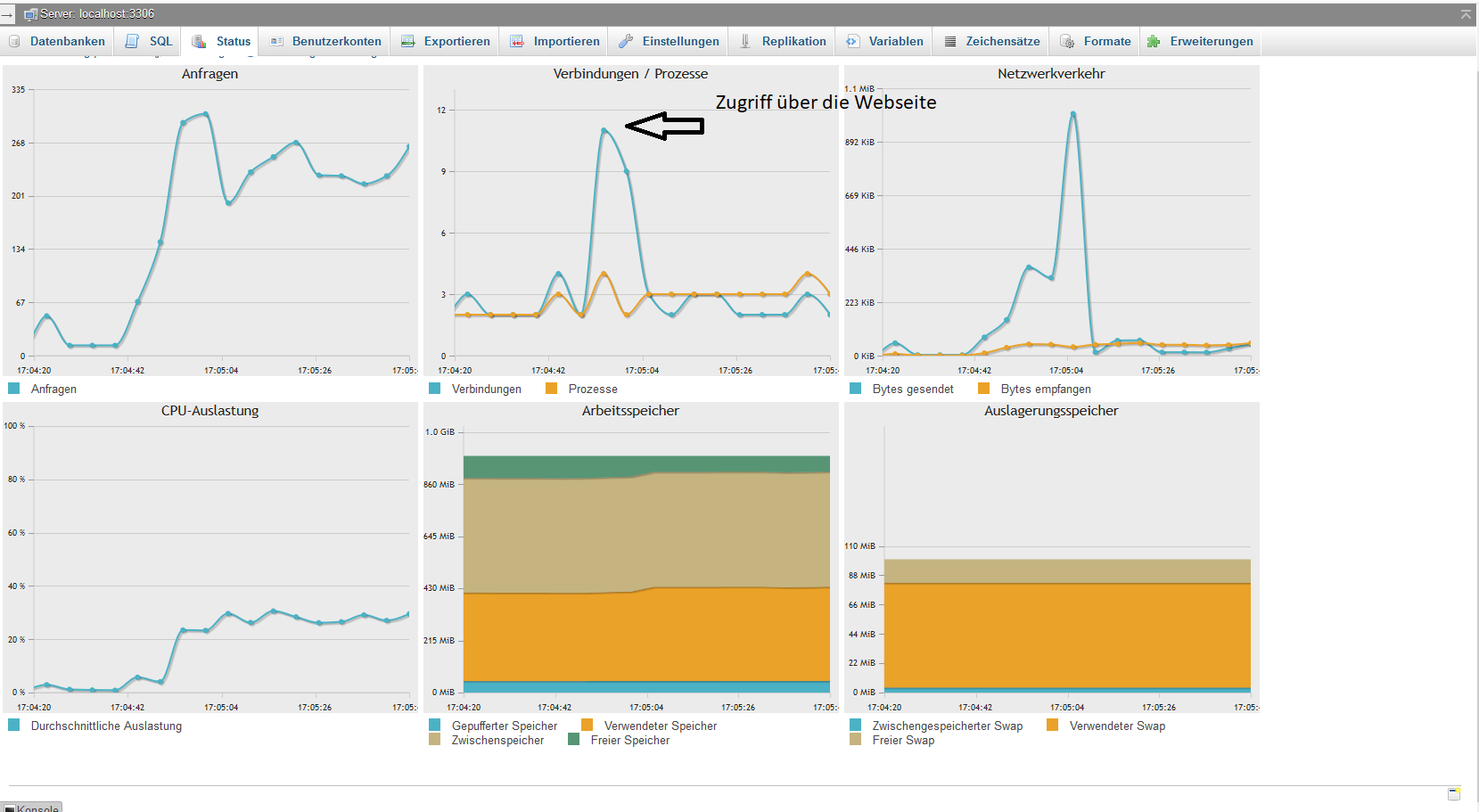
Ich habe bei mir mal in phpmyadmin nachgeschaut:
Threads cachedDokumentation
6
Anzahl der Prozesse im Prozess-Zwischenspeicher. Die Zwischenspeicher-Zugriffsrate kann mit Threads_created/Connections berechnet werden. Wenn dieser Wert rot ist, sollte der thread_cache_size erhöht werden.
Threads connectedDokumentation
2
Anzahl der momentan offenen Verbindungen.
Threads createdDokumentation
27
Anzahl der Prozesse, die zur Handhabung von Verbindungen erzeugt wurden. Wenn Threads_created hoch ist, sollten Sie eventuell die Thread_cache_size-Variable herauf setzen. (Normalerweise ergibt sich daraus keine bemerkbare Performance-Steigerung wenn eine gute Prozess-Implementierung vorliegt.)
Windows ist so offen, wie ein altes Bunkerfenster Also nie ganz dicht
Was ich damit meine: Ein Bekannter hat es mir damals so erklärt: In Linux muss man für jedes System es erstmal für das System öffnen und konfigurieren. In Windows ist schon alles offen und man muss es dicht machen, damit der Server sicher wird
hm… ich sehe auch nur dass n ganzer stapel mysql prozesse ihren spaß haben, kann man das ding eigentlich mal von sortieren nach CPU auf sortieren nach RAM stellen?
So… gelöst. Hat ein Weilchen gedauert und auf die Lösung stieß ich auch nur zufällig. Aber ich will die Lösung hier nicht vorenthalten.
Symptom:
Der Arbeitsspeicher des Nextcloud-Servers verringert sich, solange bis der Service von Nextcloud gänzlich oder weitestgehend eingestellt wird. Eine Synchronisation mit den Clients ist nicht mehr möglich, ein Einloggen per SSH auf den Server nur noch mit zeitlich großem Aufwand und Geduld möglich.
Ursache:
Bei einem nornal eingerichteten Linux-System wird der Cache-Speicher vom System verwaltet und bestimmt. Auch noch ungeklärter Ursache wurde dieser Cache-Speicher jedoch nicht oder nicht vollständig wieder freigegeben.
Lösung:
Eine auf der Konsole eingegebene Befehlsfolge leerte den Cache und gab wieder Speicher frei:
Das setzte ich nun zusammen mit einem Script, welches ich ebenfalls im Netz fand:
#!/bin/bash
#######################################################################################
#Script Name :alertmemory.sh
#Description :send alert mail when server memory is running low
#Args :
#Author :Aaron Kili Kisinga
#Email :aaronkilik@gmail.com
#License : GNU GPL-3
#######################################################################################
## get total free memory size in megabytes(MB)
free=$(free -mt | grep Total | awk '{print $4}')
## check if free memory is less or equals to 1000MB
echo $free
if [[ "$free" -le 1000 ]]; then
sync && echo 3 > /proc/sys/vm/drop_caches
fi
exit 0
Rutscht der freie Arbeitsspeicher nun unter 1 GB (-le 1000) wird der Befehl
sync && echo 3 > /proc/sys/vm/drop_caches
ausgeführt und der Arbeitsspeicher freigegeben.
Es gibt auch die Möglichkeit, den Cache-Speicher generell zu begrenzen. Das halte ich aber für mich persönlich, angesichts meiner nicht ausreichenden Kenntnisse über das “Wie” und die möglichen Folgen für keine gute Idee.
 ) aber sonst laufen dort keine weiteren Applikationen. Diesen Server habe ich ausschließlich Nextcloud zur Verfügung gestellt.
) aber sonst laufen dort keine weiteren Applikationen. Diesen Server habe ich ausschließlich Nextcloud zur Verfügung gestellt.
 Jedoch muss ich noch sagen, dass ich noch pihole benutze als zusätzlichen DNS Server im Heimnetz und noch eine fhem Instanz. Das gelbe vom Ei ist es natürlich nicht und die Webseiten sind natürlich auch nicht das schnellste, aber das wesentliche, die Synchronisation über Webdav funktioniert bei mir sehr flott
Jedoch muss ich noch sagen, dass ich noch pihole benutze als zusätzlichen DNS Server im Heimnetz und noch eine fhem Instanz. Das gelbe vom Ei ist es natürlich nicht und die Webseiten sind natürlich auch nicht das schnellste, aber das wesentliche, die Synchronisation über Webdav funktioniert bei mir sehr flott  .
.