ich habe auf meinem Proxmox 8.0 mehrere LXCs und VMs, die Problemlos vor sich hin laufen. Eine VM davon ist, eine Nextcloud Instanz. In der Instalz sind neben Nextcloud, Docker und Mysql installiert.
Mysql bzw. MariaDB ist nur für Nextcloud eingerichtet.
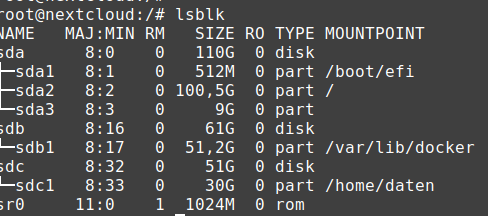
Mein Problem ist, dass das System mitteilt. dass der Speicherplatz auf “/” zu 100% belegt ist. Vor ein paar Tagen habe ich rund 30 GB hinzugefügt und dachte, dass damit das Problem behoben sei.
Aber heute schaue ich auf meine Nextcloud und siehe da, selbes Problem wie vor ein paar Tagen.
Aufgrund der Probleme habe ich vor kurzem auf Nextcloud 27.1.3 upgedated.
Wenn ich nun die beiden Dateisystem ausschließe, erhalte ich folgende Speicherbelegung:
Das ist unlogisch.
Wo ist der Speicher? Er kann nur innerhalb von /proc/ irgnedwo sein.
Aber wo?
Mit “du” bekomme ich das nicht raus.
Hat jemand eine Idee? oder vielleicht sogar die Lösung, dass der Speicher auch wieder geleert wird?
Noch etwas, mir ist aufgefallen, dass MYSQL Zeitweise sehr viel CPU braucht.
Auch ist mir aufgefallen, dass im Ordner “/tmp/” mehrere .MAD und .MAI Dateien liegen, diese sind allerdings insgesamt nur 11 GB groß und sind im obigen “du” bericht schon enthalten. Trotzdem fehlen noch etwa 80GB.
Ich hab eben ca 10GB frei gemacht, und nach ein paar Augenblicken waren diese schon wieder belegt.
Weiß einer wie ich das Problem lösen kann? oder hat zumindest einer einen Tipp wie ich auf die Lösung kommen könnte?
In den Log-Files
ein Neustart bewirkt wunder.
Nachdem ich heute Nacht neu gestartet habe, ist nun wieder 34GB frei, aber wie gesagt, da sind noch einige GB die ich nicht finde.
Kann mir jemand sagen, wie ich die fehlenden ca. 35GB finde und damit das Leck?
noch eine Info:
Das Dateisystem füllt sich bis es voll ist, dann wird automatisch wieder gelöscht, währenddessen ist der MYSQL Prozess mehrere Male aktiv und braucht auch ziemlich viel CPU.
Während die CPU so belastet ist, ist das Arbeiten mit der Nextcloud sehr träge.
Könnte es sein, dass MYSQL im Hintergrund irgendetwas macht, das die Festplatte füllt?
der Befehl du -h --max-depth=1 ist nicht sehr aussagekräftig weil du die Verzeichnisse nicht komplett scannst. Wenn etwas mit der (my)SQL Datenbank gemacht wird schreibt der Prozess s.g. “transaction logs”. Diese logs dienen der Integrität der DB und können durchaus gross werden (alle Schreibvorgänge werden dort zusätzlich abgelegt). Da du einen Zusammenhang mit der SQL DB vermutest würde ich mit auf dei DB Verzeichnisse konzentrieren - speziell transaction logs.
Es könnte z.B. sein dass du bei mehreren Usern grosse externe Speicher eingebunden hast - dann werden die Daten mehrfach in die DB eingelesen (und beanspruchen beim einlesen viel Resourcen)… sollte mE aber auch nicht viele Gigabytes brauchen… ich würde aber erst schauen ob die Annahme stimmt bevor man weiter spekuliert…
danke für deine Antwort.
Da nur 2 User auf der Nextcloud arbeiten und das nur ein oder zweimal wöchentlich, kann das mit den Transaktionslogs nicht wirkich sein, oder?
Was den Befehtl “du -h --max-depth=1” angeht, muss ich dir wiederspreichen, da der Befehl nur die Anzeige auf eine Ebene beschränkt, nicht aber den Inhalt. Die Ordner werden schon alle durchgescannt. Ich habe auch schon mit dem Befehl “ncdu” gescannt, der macht im Prinzip dasselbe wie “du” nur auf eine GUI-Art in der Konsole.
Von daher kann ich jedenfalls bestätigen, dass der Speicherplatz immer wieder gefüllt wird, und dann kann der PC/VM ihn irgendwie nicht mehr leeren. Wenn der Speicherplatz wiedermal zu 100% gefüllt ist, hilft nur ein Neustart.
Das einzige das ich heute gemacht habe ist, mich eingeloggt, von Dateien zu den Apps gewechselt, geschaut ob es Updates gibt und wieder zurück zu den Dateien gewechselt. Das war vor ca. 4 Stunden, nun ist der Speicherplatz zu 100% gefüllt und ich habe keine Ahnung wo der Speicherplatz hin ist. Heute morgen waren rund 70GB frei. Laut “du -h” sind vom System 21GB von 100GB belegt. Mir fehlen da 80 GB.
Siehe da, nach dem Neustart sind 79GB frei.
Was die externen Speicher angeht. Ja für mich habe ich einen großen externen Speicher eingebunden, aber ist nicht mal gemountet. Nur innerhalb von Nextcloud verbunden. Wenn der lokalen Speicher brauchen würde müsste der doch irgendwo angezeigt werden.
du hast recht man lernt nie aus - danke für den Tipp!
die Grundaussage steht noch - finde erst mal raus was den Platz wegnimmt… evtl. ist auch --exclude-docker der Fehler… wenn ein container den Platz verwendet siehst du das nicht…
Weder Nextcloud noch Mysql ist in Docker installiert. In Docker sind andere Dienste wie Bittwarden und Collabora. Außerdem ist Docker in einem eigenen Dateisystem.
Wie finde ich raus wer den Speicherplatz verbraucht, wenn der Speicherplatz scheinbar physisch nicht ersichtlich ist?
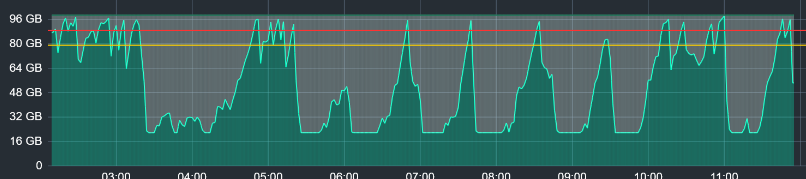
Ich sehe in meiner Überwachung, dass nicht ganz einmal pro Stunde der Speicher sich füllt.
ich bin auch kein Crack im Linux… aber das PRoblem hat mE nichts mit Nextcloud zu tun. Wenn du Ausgabe die Files und DB der Nextcloud konstant gross anzeigt scheint das Problem woanders zu sein… wo es genau ist kann ich dir nicht helfen - ich denke deine Frage ist in einem reinen Proxmox Forum besser aufgehoben.
Nutzt Du ZFS? Maybe Snapshots? Wie ist das Setup genau? In einer VM oder einem lxc? Wo liegt deine Datenbank?
Du nutzt docker - welches image?
Zeig mal die config von dem Teil - also cat docker-compose.yml
So fehlen da einfach zu viele Infos um dir zu helfen.
danke für diene Antwort.
Es handelt sie hier um eine VM. In dieser VM ist Nextcloud (27.1.3) und Mysql(10.3.39-MariaDB-0+deb10u1 Debian 10) (liegt lokal, amselben Server) installiert, nicht in Docker.
In Docker sind diese Container: Vaultwarden, Collabora, Watchtower, Portainer und Guacamole.
Das Dateisystem ist ext4, Snapshots werden hier keine gemacht.
Welche Infos können noch hilfreich sein?
die Frage ist immer noch gleich - was füllt die Disk mit Daten? wenn du keinen Weg findest die Daten im Filesystem sichtbar zu machen aber merkst dass die Disk schnell gefüllt wird kannst du mit tools wie iotop rausfinden welche Prozesse die Disk nutzen - und dort mit dem genaueren Troubleshooting weiter machen
Ok, dann hab ich das setup zumindest jetzt halbwegs verstanden.
Generell - aber nicht themenspezifisch: spring ruhig auf debian 12 - ist stable und läuft.
Dein Ansatz über du -ha --max-depth=1 zu gehen war schon passend denke ich, ist auch mein weg.
Wie du schon sagtest, wird dein temp ordner mit mai und mad dateien geflutet die riesig sind. Und hier ist glaube ich genau das Problem, denn soweit ich das kurz nachgelesen hab, sind das dateien von MariaDB, die bei fehlern erstellt werden.
Also mal ins Blaue geschossen: dein Setup der Datenbank ist nicht ideal, insbesondere nutzt du wahrscheinlich nicht innodb.
Also schau dir da mal die konfig an oder alternativ: clone die VM, installier dir postgres und zieh direkt komplett auf postgres um und spar die die manuellen korrekturen.
Falls Du bei MariaDB bleiben willst: schau wie gesagt mal nach innodb. Welche Version von mariaDB nutzt Du? ggf. ist die auch schon etwas in die tage gekommen…
Du kannst die Ausgabe pipen durch anhängen von | sort -h. Das macht das Lesen einfacher
Du solltest nur auf dem einen Laufwerk schauen. Dazu kannst du -x zusätzlich setzen. Das ganze exclude wurde ich lassen, immerhin taken for Daten auch irgendwie dazu.
Es ist auch sicher die Position in /, die Probleme macht? Ggf mit df -h prüfen.
Kannst du den Container klonen? Ggf hilft das auch zum debuggen und dann Mal die Dienste stückweise deaktivieren, bis das Problem verschwindet.
danke für die Antwort, und sorry für meine späte Antwort.
ja es handelt sich sicher um die Partition /.
Ich habe inzwischen auch herausgefunden, dass Mysql/MariaDB das Problem ist. Warum, das kann ich nicht sagen. Ich date jetzt mal auf Debian 12 up und schaue mir dann die Mirgration auf Postgresql an.
Hoffentlich ist damit das Problem dann gelöst
sobald ich damit durch bin, medle ich mich mit dem Resultat.
OK, wenn das Update das Problem beseitigen sollte: Top, dann sind wir “fertig”.
Wenn es nicht helfen sollte: Ich habe die Vermutung, dass irgend ein Logging Daten akkumuliert. Wenn das die Ursache ist, dann wird das Update wahrscheinlich nicht helfen, da die Konfiguration ja nicht zurückgesetzt wird.
Ansonsten, hast du einmal die Ursache räumlich näher einschränken können als /var/lib/mysql (meine Vermutung)? Da gibt es ein paar Unterverzeichnisse und die haben unterschiedliche Aufgaben…
Du könntest auch das Tool qdirstar-cache-writer nutzen, um zu einem Zeitpunkt von einem Verzeichnis einen “Schappschuss” zu speichern. Dann 2 Tage später noch einmal und dann kannst du mit qdirstat -c <Datei> die Schappschüsse lesen und manuell auf Zuwachs vergleichen. Wenn es im GB-Bereich ist, dürfte das gehen.
danke für deinen Input.
Den Ort, wo die “vielen Daten” abgelegt werden, habe ich zwar immer noch nicht gefunden, aber ich habe den/die Prozess/e identifiziert die läuft, wenn plötzlich soviele Daten produziert werden. Es ist definitiv MariaDB der Verursacher. Dank des Tools iotop habe ich den Schuldigen identifiziert.
Ich kann mir aber leider immer noch keinen Reim daraus machen wo die Daten abgelegt werden denn laut df -h ist das root Dateisystem (/) zeitweise mit 100% belegt aber wenn ich das ganze mit du --max-depth=1 eingrenzen will, kommen da ganz was anderes raus.
Außerdem wenn ich den Dienst mysql stoppe wird der Speicherplatz freigegeben, also muss das mit mysql zu tun haben… oder?
Gerade eben ist der Speicher wieder weniger geworden und ich hab natürlich gleich unter /var/lib/mysql nachgeschaut, aber da ist der belegte Speicher immer noch gleich. Der belegte Platz ist bei 19%. Inwischen ist er bei 92%, steigend.
Das Update von Debian Buster auf Bookworm hat jedenfall noch nichts gebraucht. Hatte ich ehrlich gesagt auch nicht erwartet.
Dann werde ich jetzt mal von Mysql/MariaDB auf Postgresql umstellen. Mal schauen ob das was bringt. Heute hat sich noch niemand an der Nextcloud angemeldet. Ich sehe auf meinem Monitoring, dass mindestens einmal die Stunde der Speicherplatz komplett verbraucht wird.
Wie gesagt im Dateisystem selber finde ich den verbrauchten Speicher aber nicht. Das ist sehr merkwürdig.
Ich habe grad einen du -h -x --max-depth=1 und gleich im Anschluss ein df -h und die stimmen nicht zusammen. Laut du verbraucht das System 38GB laut df aber 68GB.
In /tmp ist sehr viel drin, 20GB .MAI und .MAD Datein. Wobei dieses Verzeichnis wird größer. Kann das an einem Datenbankfehler liegen?
Gibt’s eine Möglichkeit die Datenbank zu überprüfen bzw. zu reparieren?
ich hab jetzt seit drei Tagen das Update auf Debian 12 Laufen und muss sagen, dass das scheinbar schon einiges gebracht hast. Die Auslastung des Root-Dateisystems ist nun zwischen 17 und 25% schwankend. Aber die 100% bzw. auch annähernd, habe ich seit Donnerstag nicht mehr gehabt.
Entweder ist das eine Wartungsarbeit die jetzt so lange gedauert hat, bis sie fertig war oder es war wirklich ein Bug oder so.
Auf jeden Fall vielen dank an Alle die mir Tipps gegeben haben.
ich hatte jetzt ca. drei Monat ruhe vor dem, dass die Festplatte immer und immer wieder gefüllt wird.
Jetzt ist aber seit ein paar Tagen wieder das Problem, dass die Festplatte gefüllt wird bis sie voll ist und ich weiß nicht was das ausgelöst hat. Außer Updates eingespielt habe ich nichts gemacht. Dieser Platz wird aber auch nicht mehr freigegeben, es sei denn ich startet den Server oder zumindest den Mysql-Dienst.
Sobald der Dienst neu gestartet ist, ist der Speicherplatz wieder freigegeben.
Warum legt MariaDB/Mysql im Ordner /tmp soviele .MAD und .MAI Dateien an? Die Größe variiert die *.MAD Dateien sind zwischen 170MB und 21GB groß. Die *.MAI sind alle 8KB groß.
An meinem Nextcloud sind 2 bis maximal 3 User gleichzeitig angemeldet, wenn überhaupt.
eine kurze Recherche hat mich zu diesem Eintrag auf Stackexchange geführt. Da ist das ganz nett erklärt. Die MAI/MAD sind temporäre Tabellen, die MariaDB im normalen Betrieb erstellt, wenn der RAM ausgeht. Dabei muss ich aber sagen, dass 21GB an Daten (MAD = Daten) schon eine ziemliche Hausnummer ist.
Eine temporäre Tabelle ist genau das: Temporär. D.h. wenn der NC core eine (!) Anfrage erhält, wird eine Session zu der DB auf gemacht und dann wenn die Daten an den Browser geschickt sind auch wieder zu gemacht. Es gibt keine temp. Tabellen in NC, die einen Request überleben (da die Session weiter genutzt werden müsste). Einzige Ausnahme wären irgendwelche OCC oder Cron Skripte, die können auch länger im Hintergrund laufen.
Ich verstehe das so, dass die Dateien da liegen bleiben und nicht in kurzer Zeit aufgeräumt werden von alleine, richtig? Dann könntest du mal mit dem Tool aria_chk versuchen, einige Infos raus zu bekommen. Ehrlich gesagt, kann ich nur selber Recherchieren, ich kann das Problem hier nicht nachstellen.
Welche Version von MySQL hast du installiert und ist das echtes MySQL oder MariaDB?
Läuft auf der Instanz auch wirklich nichts im Hintergrund? Hast du irgendwelche Custom Erweiterungen der NC drin?
Ich würde mal noch INFORMATION_SCHEMA.TABLES anschauen, ob da was zu finden ist (Quelle). Bei MariaDB könnte TEMP_TABLES_INFO (Quelle) auch noch interessant sein, wenn die Version passen würde. Eventuell kann man auch mit diesen Befehlen noch ein paar Infos raus kratzen.
Hast du extrem viele Dateien auf der Cloud (>10^9)?