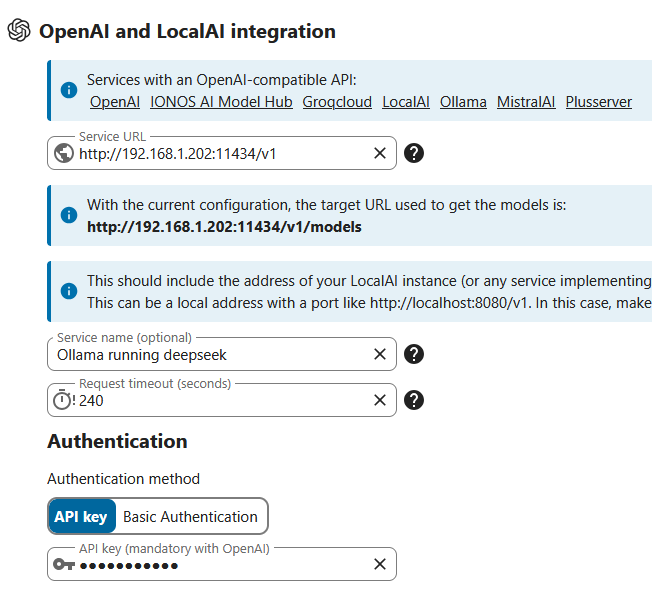
Hello!
This the config in nextcloud. I dont see any option here in the GUI to connect differently
Maybe there is something in CLI I’m not aware of?
Yes its the same container, I only have 1 instance of Ollama.
The weird thing is I dont think its is simply a problem with not using the GPU. I have a dashboard that shows the CPU usage and its basically idling.
If I remove the GPU support from Ollama and trigger a query in OpenWEBUI it goes 90%+ for 2-10 minutes while its working on it. (which is to be expected of course)
I just did a test and checked the compose logs:
6:45 queried the AI Assistant in Nextcloud, but the model is not starting to load until 6:50. Then response to 192.168.1.201 is sent with a POST 10 seconds later.
If I do the same in OpenWEBUI the model loading starts immediately.
ollama | [GIN] 2025/03/27 - 06:45:19 | 200 | 609.721µs | 192.168.1.203 | GET "/api/tags"
ollama | [GIN] 2025/03/27 - 06:45:28 | 200 | 32.139µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:45:35 | 200 | 434.47µs | 192.168.1.203 | GET "/api/tags"
ollama | [GIN] 2025/03/27 - 06:45:41 | 200 | 467.431µs | 192.168.1.201 | GET "/v1/models"
ollama | [GIN] 2025/03/27 - 06:45:59 | 200 | 34.662µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:46:29 | 200 | 38.255µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:46:59 | 200 | 28.637µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:47:29 | 200 | 29.327µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:47:59 | 200 | 34.971µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:48:17 | 200 | 587.181µs | 192.168.1.6 | GET "/v1/models"
ollama | [GIN] 2025/03/27 - 06:48:29 | 200 | 42.863µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:48:59 | 200 | 28.797µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:49:29 | 200 | 27.046µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:49:59 | 200 | 33.931µs | 127.0.0.1 | GET "/api/version"
ollama | time=2025-03-27T06:50:05.334Z level=WARN source=ggml.go:149 msg="key not found" key=qwen2.vision.block_count default=0
ollama | time=2025-03-27T06:50:05.334Z level=WARN source=ggml.go:149 msg="key not found" key=qwen2.attention.key_length default=128
ollama | time=2025-03-27T06:50:05.334Z level=WARN source=ggml.go:149 msg="key not found" key=qwen2.attention.value_length default=128
ollama | time=2025-03-27T06:50:05.334Z level=INFO source=sched.go:715 msg="new model will fit in available VRAM in single GPU, loading" model=/root/.ollama/models/blobs/sha256-aabd4debf0c8f08881923f2c25fc0fdeed24435271c2b3e92c4af36704040dbc gpu=GPU-09409fab-0702-7724-e632-4958ee1c1996 parallel=4 available=3089956864 required="1.9 GiB"
ollama | time=2025-03-27T06:50:05.416Z level=INFO source=server.go:105 msg="system memory" total="31.2 GiB" free="4.4 GiB" free_swap="108.0 KiB"
ollama | time=2025-03-27T06:50:05.416Z level=WARN source=ggml.go:149 msg="key not found" key=qwen2.vision.block_count default=0
ollama | time=2025-03-27T06:50:05.417Z level=WARN source=ggml.go:149 msg="key not found" key=qwen2.attention.key_length default=128
ollama | time=2025-03-27T06:50:05.417Z level=WARN source=ggml.go:149 msg="key not found" key=qwen2.attention.value_length default=128
ollama | time=2025-03-27T06:50:05.417Z level=INFO source=server.go:138 msg=offload library=cuda layers.requested=-1 layers.model=29 layers.offload=29 layers.split="" memory.available="[2.9 GiB]" memory.gpu_overhead="0 B" memory.required.full="1.9 GiB" memory.required.partial="1.9 GiB" memory.required.kv="224.0 MiB" memory.required.allocations="[1.9 GiB]" memory.weights.total="752.1 MiB" memory.weights.repeating="752.1 MiB" memory.weights.nonrepeating="182.6 MiB" memory.graph.full="299.8 MiB" memory.graph.partial="482.3 MiB"
ollama | llama_model_loader: loaded meta data with 26 key-value pairs and 339 tensors from /root/.ollama/models/blobs/sha256-aabd4debf0c8f08881923f2c25fc0fdeed24435271c2b3e92c4af36704040dbc (version GGUF V3 (latest))
ollama | llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
ollama | llama_model_loader: - kv 0: general.architecture str = qwen2
ollama | llama_model_loader: - kv 1: general.type str = model
ollama | llama_model_loader: - kv 2: general.name str = DeepSeek R1 Distill Qwen 1.5B
ollama | llama_model_loader: - kv 3: general.basename str = DeepSeek-R1-Distill-Qwen
ollama | llama_model_loader: - kv 4: general.size_label str = 1.5B
ollama | llama_model_loader: - kv 5: qwen2.block_count u32 = 28
ollama | llama_model_loader: - kv 6: qwen2.context_length u32 = 131072
ollama | llama_model_loader: - kv 7: qwen2.embedding_length u32 = 1536
ollama | llama_model_loader: - kv 8: qwen2.feed_forward_length u32 = 8960
ollama | llama_model_loader: - kv 9: qwen2.attention.head_count u32 = 12
ollama | llama_model_loader: - kv 10: qwen2.attention.head_count_kv u32 = 2
ollama | llama_model_loader: - kv 11: qwen2.rope.freq_base f32 = 10000.000000
ollama | llama_model_loader: - kv 12: qwen2.attention.layer_norm_rms_epsilon f32 = 0.000001
ollama | llama_model_loader: - kv 13: general.file_type u32 = 15
ollama | llama_model_loader: - kv 14: tokenizer.ggml.model str = gpt2
ollama | llama_model_loader: - kv 15: tokenizer.ggml.pre str = qwen2
ollama | llama_model_loader: - kv 16: tokenizer.ggml.tokens arr[str,151936] = ["!", "\"", "#", "$", "%", "&", "'", ...
ollama | llama_model_loader: - kv 17: tokenizer.ggml.token_type arr[i32,151936] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
ollama | llama_model_loader: - kv 18: tokenizer.ggml.merges arr[str,151387] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
ollama | llama_model_loader: - kv 19: tokenizer.ggml.bos_token_id u32 = 151646
ollama | llama_model_loader: - kv 20: tokenizer.ggml.eos_token_id u32 = 151643
ollama | llama_model_loader: - kv 21: tokenizer.ggml.padding_token_id u32 = 151643
ollama | llama_model_loader: - kv 22: tokenizer.ggml.add_bos_token bool = true
ollama | llama_model_loader: - kv 23: tokenizer.ggml.add_eos_token bool = false
ollama | llama_model_loader: - kv 24: tokenizer.chat_template str = {% if not add_generation_prompt is de...
ollama | llama_model_loader: - kv 25: general.quantization_version u32 = 2
ollama | llama_model_loader: - type f32: 141 tensors
ollama | llama_model_loader: - type q4_K: 169 tensors
ollama | llama_model_loader: - type q6_K: 29 tensors
ollama | print_info: file format = GGUF V3 (latest)
ollama | print_info: file type = Q4_K - Medium
ollama | print_info: file size = 1.04 GiB (5.00 BPW)
ollama | load: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
ollama | load: special tokens cache size = 22
ollama | load: token to piece cache size = 0.9310 MB
ollama | print_info: arch = qwen2
ollama | print_info: vocab_only = 1
ollama | print_info: model type = ?B
ollama | print_info: model params = 1.78 B
ollama | print_info: general.name = DeepSeek R1 Distill Qwen 1.5B
ollama | print_info: vocab type = BPE
ollama | print_info: n_vocab = 151936
ollama | print_info: n_merges = 151387
ollama | print_info: BOS token = 151646 '<|begin▁of▁sentence|>'
ollama | print_info: EOS token = 151643 '<|end▁of▁sentence|>'
ollama | print_info: EOT token = 151643 '<|end▁of▁sentence|>'
ollama | print_info: PAD token = 151643 '<|end▁of▁sentence|>'
ollama | print_info: LF token = 198 'Ċ'
ollama | print_info: FIM PRE token = 151659 '<|fim_prefix|>'
ollama | print_info: FIM SUF token = 151661 '<|fim_suffix|>'
ollama | print_info: FIM MID token = 151660 '<|fim_middle|>'
ollama | print_info: FIM PAD token = 151662 '<|fim_pad|>'
ollama | print_info: FIM REP token = 151663 '<|repo_name|>'
ollama | print_info: FIM SEP token = 151664 '<|file_sep|>'
ollama | print_info: EOG token = 151643 '<|end▁of▁sentence|>'
ollama | print_info: EOG token = 151662 '<|fim_pad|>'
ollama | print_info: EOG token = 151663 '<|repo_name|>'
ollama | print_info: EOG token = 151664 '<|file_sep|>'
ollama | print_info: max token length = 256
ollama | llama_model_load: vocab only - skipping tensors
ollama | time=2025-03-27T06:50:05.715Z level=INFO source=server.go:405 msg="starting llama server" cmd="/usr/bin/ollama runner --model /root/.ollama/models/blobs/sha256-aabd4debf0c8f08881923f2c25fc0fdeed24435271c2b3e92c4af36704040dbc --ctx-size 8192 --batch-size 512 --n-gpu-layers 29 --threads 2 --parallel 4 --port 37649"
ollama | time=2025-03-27T06:50:05.716Z level=INFO source=sched.go:450 msg="loaded runners" count=1
ollama | time=2025-03-27T06:50:05.716Z level=INFO source=server.go:580 msg="waiting for llama runner to start responding"
ollama | time=2025-03-27T06:50:05.716Z level=INFO source=server.go:614 msg="waiting for server to become available" status="llm server error"
ollama | time=2025-03-27T06:50:05.733Z level=INFO source=runner.go:846 msg="starting go runner"
ollama | ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ollama | ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ollama | ggml_cuda_init: found 1 CUDA devices:
ollama | Device 0: NVIDIA GeForce GTX 1060 3GB, compute capability 6.1, VMM: yes
ollama | load_backend: loaded CUDA backend from /usr/lib/ollama/cuda_v12/libggml-cuda.so
ollama | time=2025-03-27T06:50:05.805Z level=INFO source=ggml.go:109 msg=system CPU.0.LLAMAFILE=1 CUDA.0.ARCHS=500,600,610,700,750,800,860,870,890,900,1200 CUDA.0.USE_GRAPHS=1 CUDA.0.PEER_MAX_BATCH_SIZE=128 compiler=cgo(gcc)
ollama | time=2025-03-27T06:50:05.806Z level=INFO source=runner.go:906 msg="Server listening on 127.0.0.1:37649"
ollama | llama_model_load_from_file_impl: using device CUDA0 (NVIDIA GeForce GTX 1060 3GB) - 2946 MiB free
ollama | llama_model_loader: loaded meta data with 26 key-value pairs and 339 tensors from /root/.ollama/models/blobs/sha256-aabd4debf0c8f08881923f2c25fc0fdeed24435271c2b3e92c4af36704040dbc (version GGUF V3 (latest))
ollama | llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
ollama | llama_model_loader: - kv 0: general.architecture str = qwen2
ollama | llama_model_loader: - kv 1: general.type str = model
ollama | llama_model_loader: - kv 2: general.name str = DeepSeek R1 Distill Qwen 1.5B
ollama | llama_model_loader: - kv 3: general.basename str = DeepSeek-R1-Distill-Qwen
ollama | llama_model_loader: - kv 4: general.size_label str = 1.5B
ollama | llama_model_loader: - kv 5: qwen2.block_count u32 = 28
ollama | llama_model_loader: - kv 6: qwen2.context_length u32 = 131072
ollama | llama_model_loader: - kv 7: qwen2.embedding_length u32 = 1536
ollama | llama_model_loader: - kv 8: qwen2.feed_forward_length u32 = 8960
ollama | llama_model_loader: - kv 9: qwen2.attention.head_count u32 = 12
ollama | llama_model_loader: - kv 10: qwen2.attention.head_count_kv u32 = 2
ollama | llama_model_loader: - kv 11: qwen2.rope.freq_base f32 = 10000.000000
ollama | llama_model_loader: - kv 12: qwen2.attention.layer_norm_rms_epsilon f32 = 0.000001
ollama | llama_model_loader: - kv 13: general.file_type u32 = 15
ollama | llama_model_loader: - kv 14: tokenizer.ggml.model str = gpt2
ollama | llama_model_loader: - kv 15: tokenizer.ggml.pre str = qwen2
ollama | llama_model_loader: - kv 16: tokenizer.ggml.tokens arr[str,151936] = ["!", "\"", "#", "$", "%", "&", "'", ...
ollama | llama_model_loader: - kv 17: tokenizer.ggml.token_type arr[i32,151936] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
ollama | time=2025-03-27T06:50:05.968Z level=INFO source=server.go:614 msg="waiting for server to become available" status="llm server loading model"
ollama | llama_model_loader: - kv 18: tokenizer.ggml.merges arr[str,151387] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
ollama | llama_model_loader: - kv 19: tokenizer.ggml.bos_token_id u32 = 151646
ollama | llama_model_loader: - kv 20: tokenizer.ggml.eos_token_id u32 = 151643
ollama | llama_model_loader: - kv 21: tokenizer.ggml.padding_token_id u32 = 151643
ollama | llama_model_loader: - kv 22: tokenizer.ggml.add_bos_token bool = true
ollama | llama_model_loader: - kv 23: tokenizer.ggml.add_eos_token bool = false
ollama | llama_model_loader: - kv 24: tokenizer.chat_template str = {% if not add_generation_prompt is de...
ollama | llama_model_loader: - kv 25: general.quantization_version u32 = 2
ollama | llama_model_loader: - type f32: 141 tensors
ollama | llama_model_loader: - type q4_K: 169 tensors
ollama | llama_model_loader: - type q6_K: 29 tensors
ollama | print_info: file format = GGUF V3 (latest)
ollama | print_info: file type = Q4_K - Medium
ollama | print_info: file size = 1.04 GiB (5.00 BPW)
ollama | load: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
ollama | load: special tokens cache size = 22
ollama | load: token to piece cache size = 0.9310 MB
ollama | print_info: arch = qwen2
ollama | print_info: vocab_only = 0
ollama | print_info: n_ctx_train = 131072
ollama | print_info: n_embd = 1536
ollama | print_info: n_layer = 28
ollama | print_info: n_head = 12
ollama | print_info: n_head_kv = 2
ollama | print_info: n_rot = 128
ollama | print_info: n_swa = 0
ollama | print_info: n_embd_head_k = 128
ollama | print_info: n_embd_head_v = 128
ollama | print_info: n_gqa = 6
ollama | print_info: n_embd_k_gqa = 256
ollama | print_info: n_embd_v_gqa = 256
ollama | print_info: f_norm_eps = 0.0e+00
ollama | print_info: f_norm_rms_eps = 1.0e-06
ollama | print_info: f_clamp_kqv = 0.0e+00
ollama | print_info: f_max_alibi_bias = 0.0e+00
ollama | print_info: f_logit_scale = 0.0e+00
ollama | print_info: n_ff = 8960
ollama | print_info: n_expert = 0
ollama | print_info: n_expert_used = 0
ollama | print_info: causal attn = 1
ollama | print_info: pooling type = 0
ollama | print_info: rope type = 2
ollama | print_info: rope scaling = linear
ollama | print_info: freq_base_train = 10000.0
ollama | print_info: freq_scale_train = 1
ollama | print_info: n_ctx_orig_yarn = 131072
ollama | print_info: rope_finetuned = unknown
ollama | print_info: ssm_d_conv = 0
ollama | print_info: ssm_d_inner = 0
ollama | print_info: ssm_d_state = 0
ollama | print_info: ssm_dt_rank = 0
ollama | print_info: ssm_dt_b_c_rms = 0
ollama | print_info: model type = 1.5B
ollama | print_info: model params = 1.78 B
ollama | print_info: general.name = DeepSeek R1 Distill Qwen 1.5B
ollama | print_info: vocab type = BPE
ollama | print_info: n_vocab = 151936
ollama | print_info: n_merges = 151387
ollama | print_info: BOS token = 151646 '<|begin▁of▁sentence|>'
ollama | print_info: EOS token = 151643 '<|end▁of▁sentence|>'
ollama | print_info: EOT token = 151643 '<|end▁of▁sentence|>'
ollama | print_info: PAD token = 151643 '<|end▁of▁sentence|>'
ollama | print_info: LF token = 198 'Ċ'
ollama | print_info: FIM PRE token = 151659 '<|fim_prefix|>'
ollama | print_info: FIM SUF token = 151661 '<|fim_suffix|>'
ollama | print_info: FIM MID token = 151660 '<|fim_middle|>'
ollama | print_info: FIM PAD token = 151662 '<|fim_pad|>'
ollama | print_info: FIM REP token = 151663 '<|repo_name|>'
ollama | print_info: FIM SEP token = 151664 '<|file_sep|>'
ollama | print_info: EOG token = 151643 '<|end▁of▁sentence|>'
ollama | print_info: EOG token = 151662 '<|fim_pad|>'
ollama | print_info: EOG token = 151663 '<|repo_name|>'
ollama | print_info: EOG token = 151664 '<|file_sep|>'
ollama | print_info: max token length = 256
ollama | load_tensors: loading model tensors, this can take a while... (mmap = true)
ollama | load_tensors: offloading 28 repeating layers to GPU
ollama | load_tensors: offloading output layer to GPU
ollama | load_tensors: offloaded 29/29 layers to GPU
ollama | load_tensors: CPU_Mapped model buffer size = 125.19 MiB
ollama | load_tensors: CUDA0 model buffer size = 934.70 MiB
ollama | llama_init_from_model: n_seq_max = 4
ollama | llama_init_from_model: n_ctx = 8192
ollama | llama_init_from_model: n_ctx_per_seq = 2048
ollama | llama_init_from_model: n_batch = 2048
ollama | llama_init_from_model: n_ubatch = 512
ollama | llama_init_from_model: flash_attn = 0
ollama | llama_init_from_model: freq_base = 10000.0
ollama | llama_init_from_model: freq_scale = 1
ollama | llama_init_from_model: n_ctx_per_seq (2048) < n_ctx_train (131072) -- the full capacity of the model will not be utilized
ollama | llama_kv_cache_init: kv_size = 8192, offload = 1, type_k = 'f16', type_v = 'f16', n_layer = 28, can_shift = 1
ollama | llama_kv_cache_init: CUDA0 KV buffer size = 224.00 MiB
ollama | llama_init_from_model: KV self size = 224.00 MiB, K (f16): 112.00 MiB, V (f16): 112.00 MiB
ollama | llama_init_from_model: CUDA_Host output buffer size = 2.34 MiB
ollama | llama_init_from_model: CUDA0 compute buffer size = 299.75 MiB
ollama | llama_init_from_model: CUDA_Host compute buffer size = 19.01 MiB
ollama | llama_init_from_model: graph nodes = 986
ollama | llama_init_from_model: graph splits = 2
ollama | time=2025-03-27T06:50:06.720Z level=INFO source=server.go:619 msg="llama runner started in 1.00 seconds"
ollama | [GIN] 2025/03/27 - 06:50:13 | 200 | 8.078303888s | 192.168.1.201 | POST "/v1/chat/completions"
ollama | [GIN] 2025/03/27 - 06:50:29 | 200 | 28.096µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:50:59 | 200 | 30.911µs | 127.0.0.1 | GET "/api/version"
ollama | [GIN] 2025/03/27 - 06:51:29 | 200 | 29.373µs | 127.0.0.1 | GET "/api/version"