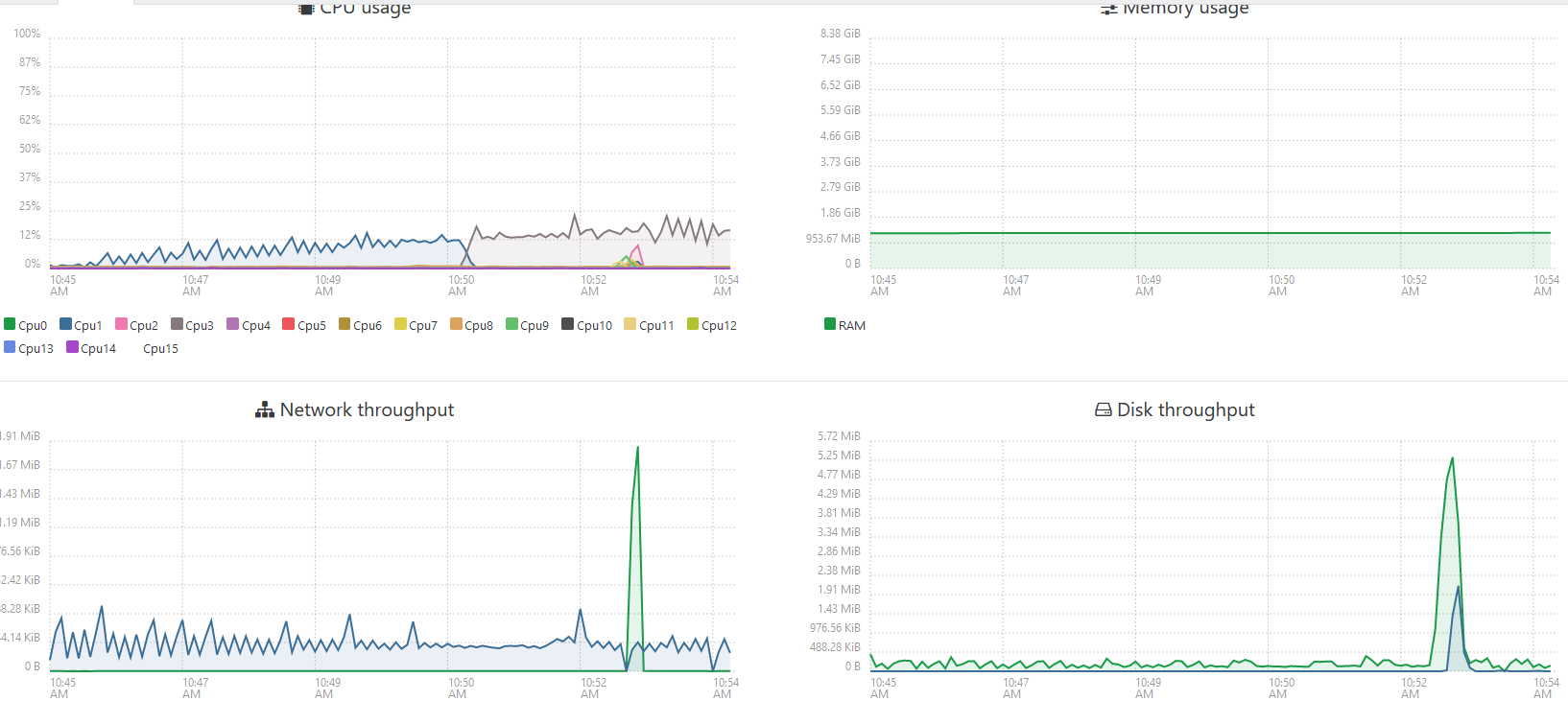
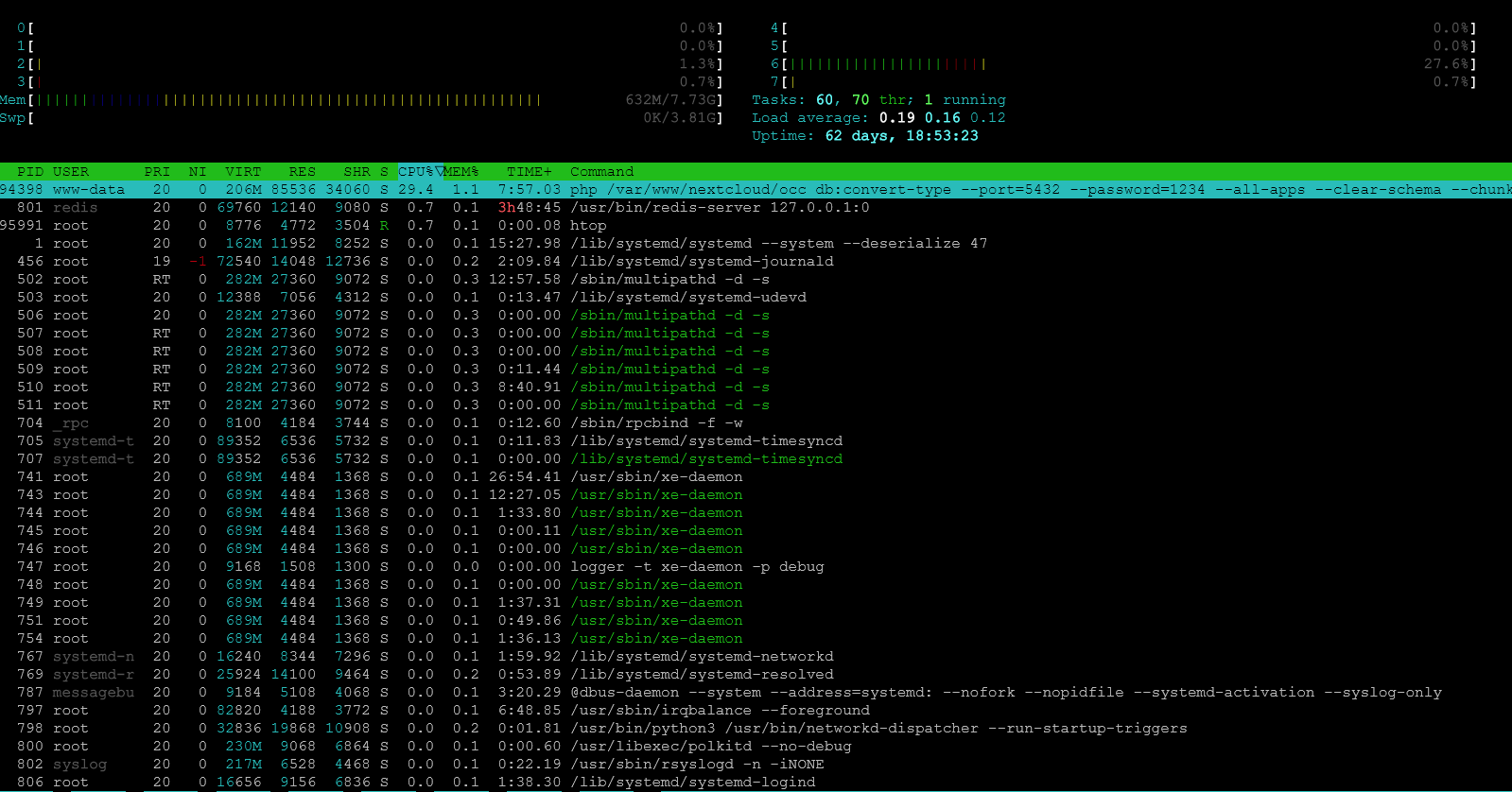
I have 100Gb mysql db. Trying convertation to postgre, but it takes about forever.
Total 219283353 chunks, in first 30min about 200-400k done with ETA 2days, then it slow down and ETA became 20+ days. So no way to complete this. Traffic on VM ~50Kb\s.
Tried default chunk size and 100Mb with --chunk-size key.
Is it works as intended or more looks like bad perfomance\memory leak?
The --chunk-size option expects an integer value. It defaults to 1000 but you might try 10000. If you specified 100Mb I think it would have been cast to 100 further slowing things slow (I would expect anyhow).
What does the CPU or Disk I/O utilization look like on the app server and the db servers?
That only one key that required for this method and not exist at official doc)
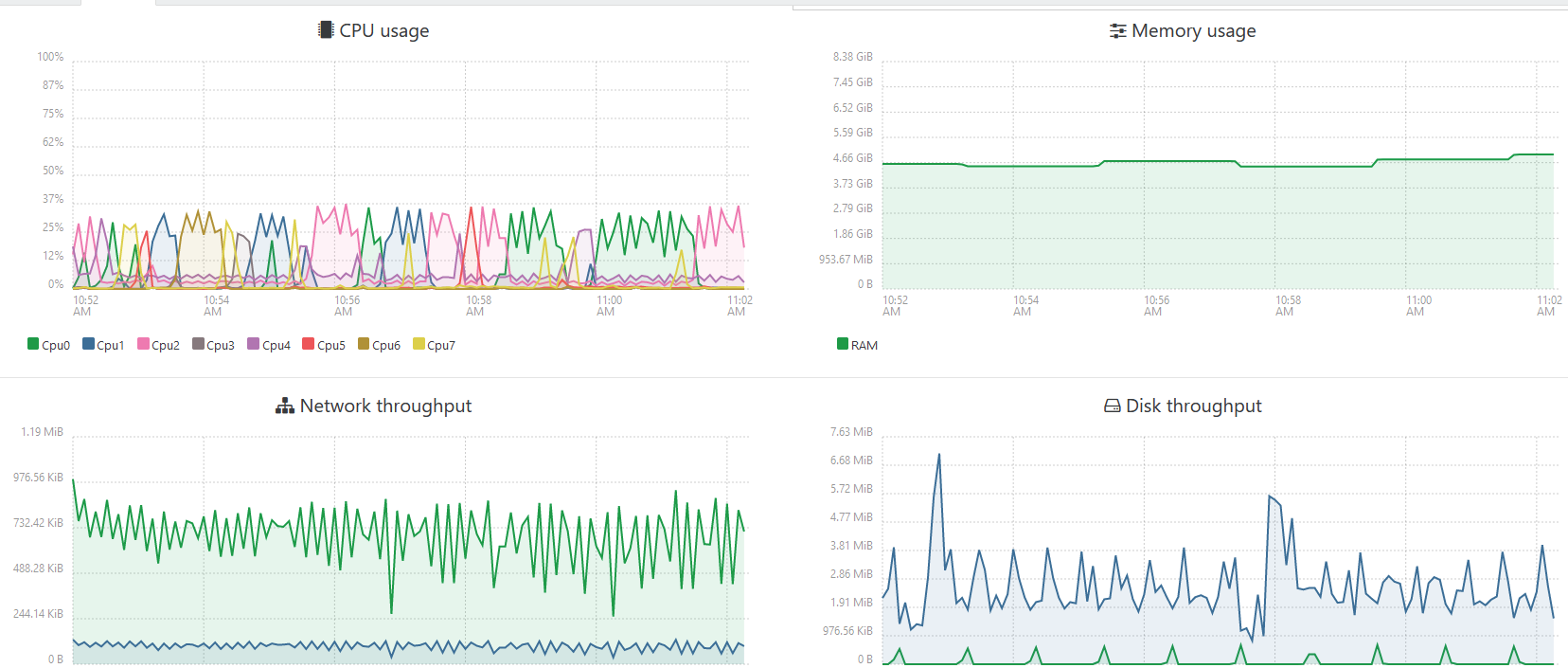
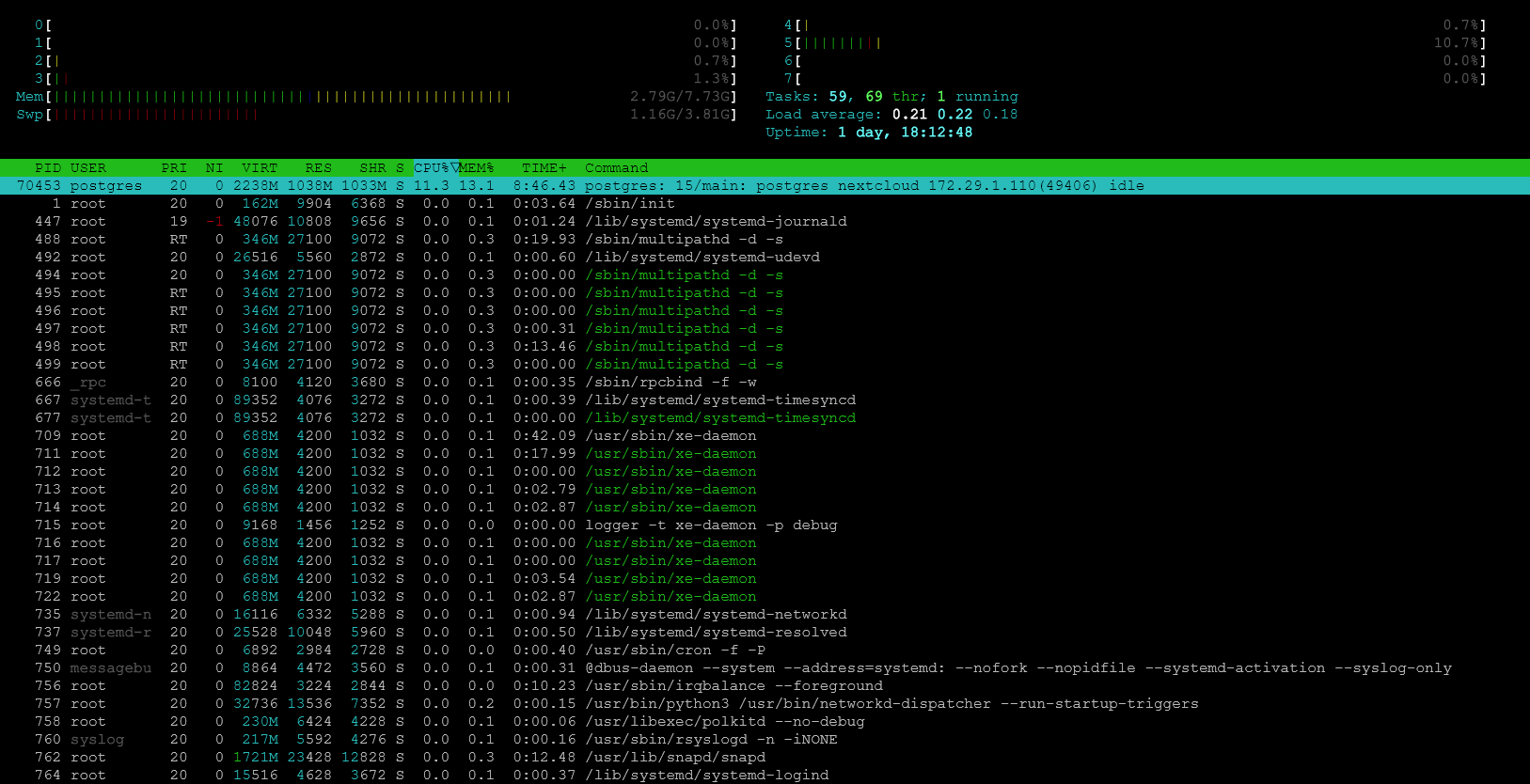
Tested with chunk size 10000.
Before calculation of oc_filecache table, with default size i wait for about 5min. Now it takes about 20min.
First time failed by timeout, 2nd started.
Looks much better, but still very slow. Also process a bit slow down after first million.