The Basics
- Nextcloud Server version (e.g., 29.x.x):
Nextcloud AIO v12.8.0
- Operating system and version (e.g., Ubuntu 24.04):
Ubuntu 24.04.4 LTS
- Web server and version (e.g, Apache 2.4.25):
Whatever is in AIO
- Reverse proxy and version _(e.g. nginx 1.27.2)
nginx 1.29.1
- PHP version (e.g, 8.3):
8.3.6
- Is this the first time you’ve seen this error? (Yes / No):
no
- When did this problem seem to first start?
Months ago
- Installation method (e.g. AlO, NCP, Bare Metal/Archive, etc.)
AIO
- Are you using CloudfIare, mod_security, or similar? (Yes / No)
no
Summary of the issue you are facing:
After running for an random amount of time, users start getting a 502 error when going to the NextCloud page. I have to recycle docker (service docker restart). Once docker is recycled, I have to go to the AIO containers page and Stop containers and then Start containers for NextCloud to come back and be accessible.

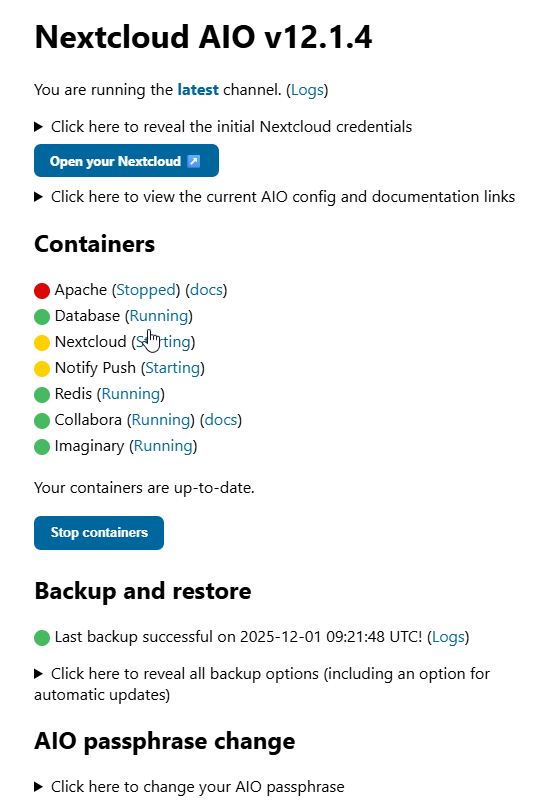
AIO and Ubuntu have both been upgraded. The issue still persists. I am unsure where/how to troubleshoot from here.
Steps to replicate it (hint: details matter!):
1. Just wait. Eventually it will fail.
Log entries
When I recycle docker I lose the logs. I need to get them next time.
Web server / Reverse Proxy
The output of your Apache/nginx/system log in /var/log/____:
TBD
Configuration
Nextcloud
The output of occ config:list system or similar is best, but, if not possible, the contents of your config.php file from /path/to/nextcloud is fine (make sure to remove any identifiable information!):
PASTE HERE
Apps
* activity: 5.0.0
* admin_audit: 1.22.0
* bruteforcesettings: 5.0.0
* cloud_federation_api: 1.16.0
* comments: 1.22.0
* dav: 1.34.2
* federatedfilesharing: 1.22.0
* files: 2.4.0
* files_automatedtagging: 3.0.3
* files_downloadlimit: 5.0.0-dev.0
* files_pdfviewer: 5.0.0
* files_reminders: 1.5.0
* files_sharing: 1.24.1
* files_trashbin: 1.22.0
* files_versions: 1.25.0
* flow_notifications: 3.0.0
* logreader: 5.0.0
* lookup_server_connector: 1.20.0
* nextcloud-aio: 0.8.0
* nextcloud_announcements: 4.0.0
* notifications: 5.0.0
* notify_push: 1.3.1
* oauth2: 1.20.0
* password_policy: 4.0.0
* privacy: 4.0.0
* profile: 1.1.0
* provisioning_api: 1.22.0
* recommendations: 5.0.0
* related_resources: 3.0.0
* richdocuments: 9.0.5
* serverinfo: 4.0.0
* settings: 1.15.1
* support: 4.0.0
* survey_client: 4.0.0
* systemtags: 1.22.0
* text: 6.0.1
* theming: 2.7.0
* twofactor_backupcodes: 1.21.0
* updatenotification: 1.22.0
* user_status: 1.12.0
* viewer: 5.0.0
* webhook_listeners: 1.3.0
* workflowengine: 2.14.0
Disabled:
* app_api: 32.0.0 (installed 32.0.0)
* calendar: 6.2.1 (installed 6.2.1)
* cfg_share_links: 7.0.1 (installed 7.0.1)
* circles: 32.0.0 (installed 32.0.0)
* contacts: 8.3.6 (installed 8.3.6)
* contactsinteraction: 1.13.1 (installed 1.13.1)
* dashboard: 7.12.0 (installed 7.12.0)
* deck: 1.16.3 (installed 1.16.3)
* encryption: 2.20.0
* federation: 1.22.0 (installed 1.22.0)
* files_external: 1.24.1
* firstrunwizard: 5.0.0 (installed 5.0.0-dev.0)
* notes: 4.13.1 (installed 4.13.1)
* photos: 5.0.0 (installed 5.0.0-dev.1)
* sharebymail: 1.22.0 (installed 1.22.0)
* suspicious_login: 10.0.0
* tasks: 0.17.1 (installed 0.17.1)
* twofactor_nextcloud_notification: 6.0.0
* twofactor_totp: 14.0.0 (installed 14.0.0)
* user_ldap: 1.23.0
* weather_status: 1.12.0 (installed 1.12.0)
