This is how I mount ncdata persistently (when using Docker, but can use it anytime needed).
Preparations:
Create a mountpoint for the external drive and ncdata
sudo mkdir /media/ncp
Find UUID of external drive
ls -lh /dev/disk/by-uuid/
(Mine looks like this)
total 0
lrwxrwxrwx 1 root root 15 Aug 11 09:10 29075e46-f0d4-44e2-a9e7-55ac02d6e6cc -> …/…/mmcblk0p2
lrwxrwxrwx 1 root root 10 Aug 11 09:10 35e98a80-8895-41f4-93e7-39940a1fda70 -> …/…/sda1
lrwxrwxrwx 1 root root 15 Aug 11 09:10 9304-D9FD -> …/…/mmcblk0p1
Add a ligne to /etc/fstab
sudo nano /etc/fstab
add line for your drive (copy/paste your drive’s UUID and change ext4 to btrfs if needed):
UUID=YourDrive’sUUID /media/ncp ext4 rw,users 0 0
mount the drive
sudo mount -a
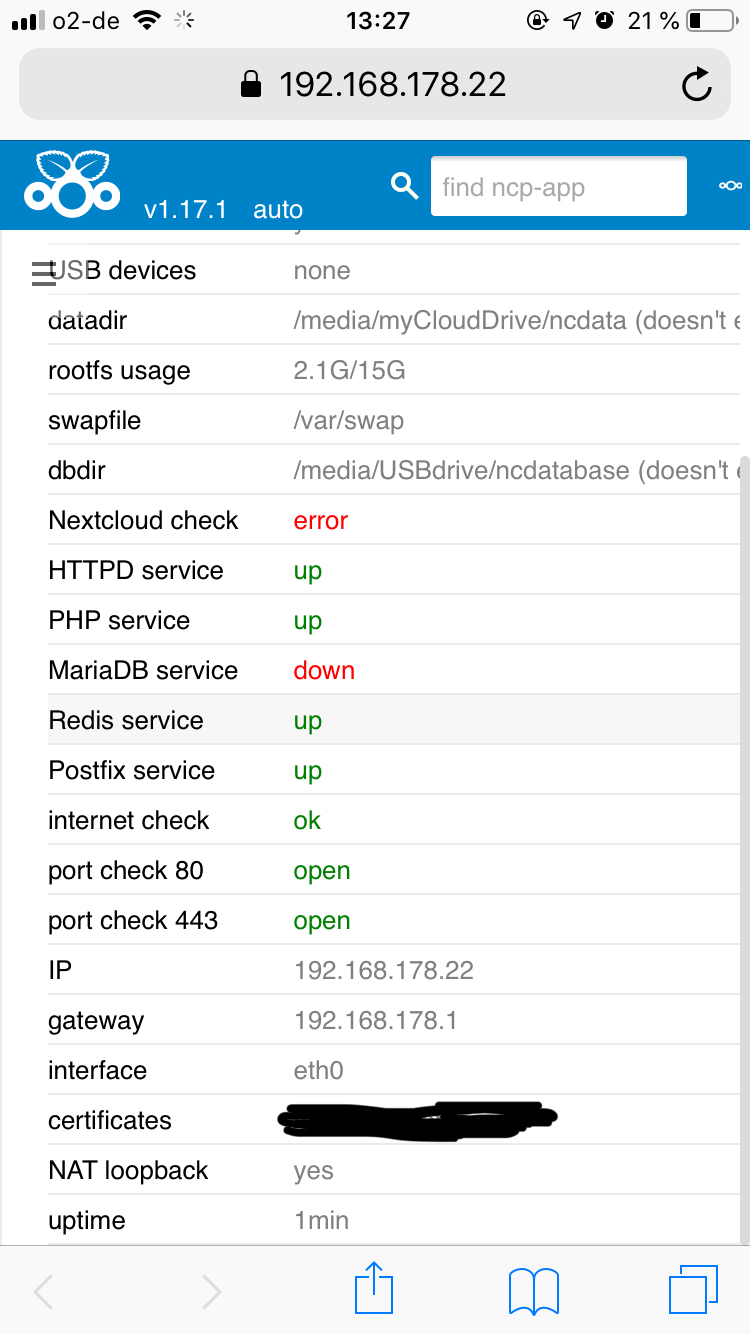
Another one here. The install (Berryboot. DB on a USB stick. Data files and backups on a couple of USB HD. All appear to be mounted correctly when checked. Config files and data all backed up) had been working fine until today when the MariaDB down and Next Cloud error came up without me doing anything. I had been on 16.05. Tried switching up to NC 17. That got rid of the NC error but the DB is still down. Added the line suggested by omni but no change. DB still down.
systemctl status mariadb.service throws up the following -
Thing is the DB is still down. Any pointers would be great. Thanks.
NextCloudPi version
v1.18.0
NextCloudPi image
NextCloudPi_03-09-19
distribution
Raspbian GNU/Linux 9 \n \l
automount
yes
USB devices
sda sdb sdc
datadir
/var/www/nextcloud/data
data in SD
yes
data filesystem
aufs
data disk usage
1.8G/116G
rootfs usage
1.8G/116G
swapfile
none
dbdir
/var/lib/mysql
Nextcloud check
ok
Nextcloud version
17.0.0.9
HTTPD service
up
PHP service
up
MariaDB service
down
Redis service
up
Postfix service
up
internet check
ok
port check 80
open
port check 443
open
IP
xxx.xxx.x.xxx
gateway
xxx.xxx.x.x
interface
eth0
certificates
xxxxxxx.xxxx.xxx
NAT loopback
yes
uptime
53min
From that is looks to me like the DB is being looked for somewhere other than where it should i.e. on the USB stick at /media/disk/var/lib/mysql - if I knew how to point it to there I would have a go at that. Can you tell I don’t have much of an idea what I’m doing
edit1: Maybe this could be of some help. You will see I have rolled back to a saved configuration which is where this all started from…
edit2: Decided that seeing as I had backups as guided by How to backup and restore using nc snapshot I may as well use them. I cut my losses and did a new install. Restored the configuration, database and data files. All seems to be as it was before the meltdown. It would be helpful to know what may have caused it to help avoid similar issues in the future.
Thank you @nachoparker for all the work you have put into helping people like me to help themselves in the dark.
Job for mysql.service failed because the control process exited with error code.
See “systemctl status mysql.service” and “journalctl -xe” for details.
pi@nextcloudpi:~ $ systemctl status mysql.service
● mysql.service - LSB: Start and stop the mysql dat Loaded: loaded (/etc/init.d/mysql; generated)
Active: failed (Result: exit-code) since Wed 202 Docs: man:systemd-sysv-generator(8)
Process: 9553 ExecStart=/etc/init.d/mysql start (
Feb 19 17:06:53 nextcloudpi mysqld_safe[9787]: mysqFeb 19 17:07:25 nextcloudpi /etc/init.d/mysql[10204Feb 19 17:07:25 nextcloudpi /etc/init.d/mysql[10204Feb 19 17:07:25 nextcloudpi /etc/init.d/mysql[10204Feb 19 17:07:25 nextcloudpi /etc/init.d/mysql[10204Feb 19 17:07:25 nextcloudpi /etc/init.d/mysql[10204Feb 19 17:07:25 nextcloudpi mysql[9553]: Starting MFeb 19 17:07:25 nextcloudpi systemd[1]: mysql.serviFeb 19 17:07:25 nextcloudpi systemd[1]: mysql.serviFeb 19 17:07:25 nextcloudpi systemd[1]: Failed to s